Çfarë është testi fpu. Testimi i performancës
Një procesor i shpejtë është i mrekullueshëm! Sidoqoftë, ka mjaft faktorë që ndikojnë në performancën e procesorit. Ka njerëz që matin shpejtësinë ekskluzivisht në gigahertz - sa më shumë, aq më mirë. Ata që janë më me përvojë zakonisht vlerësojnë performancën e një procesori ose me teste speciale ose nga mënyra se si ai përballet me përpunimin e informacionit në aplikacione reale që kërkojnë sasi të mëdha llogaritjesh (grafika 3D, kompresim video, etj.). Duke marrë parasysh që shumica e aplikacioneve dhe lojërave moderne kërkojnë një sasi të madhe llogaritjesh veçanërisht për numrat realë (numrat me pikë lundruese), performanca e përgjithshme e procesorit varet nga sa shpejt i përpunon ato. Për këto qëllime, procesori ka një modul të veçantë të quajtur njësi me pikë lundruese (FPU) - një modul llogaritjeje me pikë lundruese. Në të njëjtën kohë, performanca e këtij moduli varet jo vetëm nga frekuenca e funksionimit të procesorit, por edhe nga karakteristikat e tij të projektimit.
Në fillim të evolucionit të kompjuterëve të pajtueshëm me IBM, llogaritjet mbi numrat realë kryheshin nga një bashkëprocesor matematikor, i projektuar veçmas nga procesori qendror. Sidoqoftë, tashmë në procesorin e 486-të, Intel përdori një modul të integruar të llogaritjes me pikë lundruese, duke rritur ndjeshëm shpejtësinë e procesorit me numra realë. Më pas, prodhues të tjerë të procesorëve për kompjuterë personalë kaluan në FPU të integruar.
Vini re se kur punoni me numra realë, ekziston e njëjta nuancë si në operacionet me numra të plotë - një komandë nuk mund të ekzekutohet në një cikël orësh të procesorit (shih artikullin "Pse një procesori ka nevojë për një transportues", "KB" Nr. /2003) . Dhe nëse në 486 përpunues një tubacion me pesë faza tashmë kishte filluar të përdoret për përpunimin e udhëzimeve të numrave të plotë, atëherë FPU nuk ishte ende një lloj tubacioni, d.m.th. komanda tjetër me pikë lundruese gjithmonë duhej të priste që ajo e mëparshme të përfundonte. Kjo ngadalësoi ndjeshëm performancën e procesorit me aplikacionet multimediale. Dhe këta të fundit në atë kohë tashmë kishin filluar të merrnin vrull me shpejtësi në "kërkesat" e tyre. Prandaj, është mjaft e natyrshme që Intel, duke filluar me procesorët Pentium, filloi të përdorë tubacionin jo vetëm në numër të plotë, por edhe në operacione reale. AMD Corporation, nga ana tjetër, mori një rrugë paksa të ndryshme - në vend të tubacionit të FPU, ajo filloi të prezantojë teknologjinë 3DNow në produktet e saj, e cila synonte gjithashtu rritjen e performancës në operacionet me numra realë. Kjo teknologji është përballur me shumë sfida në zbatimin e saj. Unë mendoj se shumë njerëz kujtojnë se si AMD K6-2, i krijuar për të konkurruar me Pentium II në operacionet me numra të plotë, ishte tridhjetë për qind prapa tij në përpunimin e numrave realë.
Por, siç thonë ata, ju mësoni nga gabimet, kështu që në Athlons dhe procesorët pasues, AMD kaloi në një FPU të llojit të tubacionit, për më tepër, në procesorët e rinj, AMD përdori jo vetëm superpipelinimin, por edhe superskalaritetin në modulin me pikë lundruese. një procesor filloi të kishte, përafërsisht, tre module FPU, secila prej të cilave merr pjesë në llogaritjet me pikë lundruese, me fjalë të tjera, me lëshimin e procesorëve Athlon/.
08.08.2012
Deri në ardhjen e procesorëve Intel Core, askush nuk mendoi për konceptin e "efikasitetit thelbësor", por vlera e tij doli të ishte shumë më e lartë se frekuencat dhe madhësitë e cache-it të vlerësuara më parë. Por si mund ta paraqesim efikasitetin e bërthamës në numra? Ne ju ofrojmë një nga opsionet, duke përdorur të cilat ju mund të vlerësoni performancën nga një kënd tjetër.
Më lejoni të bëj një rezervë menjëherë se rezultatet e testit të sotëm nuk përfaqësojnë të vërtetën përfundimtare. Dhe nuk pretendon të jetë 100% i saktë. Kur përdorni parime të tjera të testimit, mund të merrni rezultate të ndryshme, por mua më duket se kjo metodë e veçantë bën të mundur nxjerrjen e përfundimeve adekuate që konfirmohen nga historia.
Çfarë e bën një procesor të veçantë të demonstrojë performancën e duhur? Kjo pyetje mundoi shumë amatorë dhe profesionistë nga bota e hekurit. Për një kohë të gjatë, masa kryesore e performancës ishte shpejtësia e orës. Pak më vonë, vëmendja kaloi në frekuencën e autobusit të përparmë, pastaj në vëllimin e cache-ve dhe më pas në numrin e bërthamave. Por gjithmonë neglizhohej diçka që në fakt ndikoi drejtpërdrejt në shpejtësinë e llogaritjeve.
Kjo është diçka që është padyshim performanca e pastër e dy njësive më të rëndësishme të procesorëve modernë x86: njësia e plotë (ALU - Njësia Logjike Aritmetike) dhe Njësia me pikë lundruese (FPU - Njësia me Pika Floating). Është e përbashkëta e karakteristikave të tyre ajo që përcakton konceptin e arkitekturës - dhe ky koncept nuk ka të bëjë fare me cache-in apo frekuencën, ndërkohë që ndikon drejtpërdrejt në performancën e përgjithshme të procesorit.
Pra, përpara se të fillojmë një studim të madh, le të kuptojmë se çfarë janë këto blloqe, çfarë bëjnë dhe si janë rregulluar. Siç thashë tashmë, ky material nuk flet për punën me memorien, cache dhe shtesat e tjera, ne do të flasim vetëm për ALU dhe FPU, dhe, natyrisht, për dy komponentët e tyre të rëndësishëm - tubacionet dhe një njësi të parashikimit të degëve. Epo, le të flasim pak për teknologjinë Hyper-Threading nga Intel, pasi ajo ndikon drejtpërdrejt në performancën e bërthamës kur kryen operacione të thjeshta.
Blloku i operacioneve me numra të plotë
Blloku i parë dhe kryesor i procesorit. Megjithëse, do të ishte më e saktë të thuash jo një bllok, por blloqe, pasi ka disa prej tyre në procesorë. Përafërsisht, në agimin e zhvillimit, praktikisht nuk kishte asgjë në procesor përveç këtij blloku. Që nga modelet e para deri te përbindëshat e sotëm, misioni kryesor i ALU nuk ka ndryshuar. Punon ende me numrat e thjeshtë (të plotë), duke kryer veprime të mbledhjes, zbritjes, krahasimit, shndërrimit të numrave; kryen veprime të thjeshta logjike, si dhe ndërrime bit.
Ju lutemi vini re se ALU-së nuk i janë caktuar detyrat e shumëzimit dhe ndarjes, dhe gjithçka sepse këto lloje llogaritjesh janë mjaft të rralla, dhe si rezultat, atyre iu nda blloku i tyre - një "shumësues i plotë", falë të cilit ishte e mundur të rritej performancën e ALU-së, duke e liruar atë nga detyra jo standarde. Operacionet e ndarjes i caktohen gjithashtu shumëzuesit dhe kryhen duke përdorur një tabelë të veçantë konstante. Këtu është një bllok shumë i thjeshtë, performanca e të cilit ndikon drejtpërdrejt në performancën e procesorit në shumë detyra, për shembull, aplikacionet e zyrës, programe të shumta specifike për llogaritjet, etj.
Njësi me pikë lundruese
Ky bllok u shfaq në procesorë shumë më vonë se ALU, dhe në fillim u konsiderua edhe si një bashkëprocesor. Megjithatë, më vonë ai megjithatë migroi në thelbin e procesorit kryesor dhe që atëherë ka qenë pjesa integrale dhe shumë e rëndësishme e tij (siç është rasti me ALU, ky bllok nuk është i vetëm në procesor). Siç nënkupton edhe emri i saj, detyra kryesore e FPU-së janë pikërisht operacionet në numrat me pikë lundruese.
Meqenëse ky bllok u shfaq si pjesë e CPU-së, ngarkesa në të është rritur gjatë gjithë kohës, gjë që përfundimisht çoi në faktin se ngarkesa në FPU më shpesh tejkalon ngarkesën në ALU. Për më tepër, duke pasur parasysh shkathtësinë e lartë të këtij blloku, atij iu shtuan gradualisht funksione shtesë, në veçanti, për momentin është ai që funksionon me të gjitha rezolucionet e transmetimit dhe përpunon të dhënat vektoriale, nga të cilat tashmë ka shumë në procesorët modernë . Performanca e procesorit në shumicën dërrmuese të aplikacioneve varet nga performanca e këtij blloku, veçanërisht në multimedia, lojëra, punë 3D me fotografi, etj.
Transportues
Dihet se çdo operacion në procesor kërkon një kohë të caktuar përpunimi dhe këto të dhëna, pa ekzagjerim, janë një sasi e madhe. Për të optimizuar punën me ta dhe për të thjeshtuar ekzekutimin e tyre, për të rritur shpejtësinë e punës, u shpik një transportues.
Parimi i tij është i ngjashëm me funksionimin e një rripi transportues konvencional në një fabrikë: një pjesë kalon gradualisht nëpër disa stacione të palëvizshme të punëtorëve që e përpunojnë atë, dhe secili kryen vetëm një operacion në të. Në vend të një pjese, procesori përmban të dhëna, të cilat gjithashtu kalojnë në mënyrë sekuenciale në disa faza. Natyrisht, kjo qasje bëri të mundur reduktimin e ndjeshëm të kohës së papunë të secilit bllok individual të procesorit, domethënë të rrisë ndjeshëm performancën e tij në krahasim me përpunimin ekskluziv të të dhënave.
Megjithatë, transportuesi ka edhe disavantazhe që janë pasojë e avantazheve të tij. Kryesorja është nevoja për të rivendosur të gjithë tubacionin për shkak të një ndryshimi të papritur në rrjedhën e programit. Më shpesh, kjo ndodh kur në kod përdoren deklarata të kushtëzuara, të cilat, në varësi të kushteve, ndryshojnë të dhëna dhe shtigje të mëtejshme.
Ekziston një pikë tjetër e rëndësishme: tubacionet e procesorëve të ndryshëm kanë numër të ndryshëm fazash. Avantazhi i tubacioneve të shkurtra është se ato ju lejojnë të arrini performancë më të lartë në të njëjtën frekuencë, ndërsa një tubacion i gjatë ju ndihmon të arrini shpejtësi më të larta të orës. Një shembull i thjeshtë i jetës reale: procesorët AMD Athlon XP dhe Athlon 64 me arkitekturë K7 dhe K8, përkatësisht, të cilët dikur konkurronin me procesorët Intel Pentium 4 me arkitekturë NetBurst. Siç e mbani mend me siguri, shumë procesorë në këto linja ishin shumë afër njëri-tjetrit në performancë, por në të njëjtën kohë ata ishin kategorikisht të ndryshëm në karakteristika. Në veçanti, Athlon 64 3200+, me shpejtësi 2200 megaherz, më së shpeshti ia kalonte Pentium 4 në 3200 megahertz. Arsyeja për këtë fakt është gjatësia e ndryshme e tubacionit: nëse AMD përdorte tradicionalisht një të shkurtër 12-fazor, atëherë Intel në Pentium 4 përdori një shumë më të gjatë me 20 faza, dhe pak më vonë - 31 faza! Prandaj ndryshimi i dukshëm në performancë.
Blloku i parashikimit të degës (blloku i parashikimit të degës së kushtëzuar)
Shfaqja e këtij blloku ishte e pashmangshme pas shfaqjes së transportuesit. Problemi i shpallur tashmë i deklaratave të kushtëzuara dhe rivendosja e plotë e pashmangshme e tubacionit ndikuan ndjeshëm në performancën e përgjithshme, pasi në disa aplikacione përqindja e defekteve gjatë përpunimit të të dhënave thjesht shkoi jashtë shkallës.
Pra, çfarë bën ky bllok? Është e thjeshtë - funksionon si një shikues i rregullt i procesorit, domethënë, duke tejkaluar ngjarjet (lexoni llogaritjet e një dege të gabuar të të dhënave), përcakton nëse një tranzicion i kushtëzuar do të ekzekutohet apo jo. Natyrisht, nuk ka fat në llum kafeje. Për momentin, kryesore dhe prioritare është metoda dinamike e parashikimit të tranzicioneve, në të cilën blloku i parashikimit të degës jo vetëm që analizon të dhënat dhe udhëzimet që përgatiten për përpunim nga procesori, por gjithashtu analizon historinë e tranzicioneve të ngjashme, të cilat ai vetë. grumbullohet. Për shkak të faktit se ai monitoron vazhdimisht rezultatin përfundimtar (pavarësisht nëse e hamendësoi saktë apo jo) dhe e krahason atë me parashikimin e tij, duke plotësuar statistikat e tij, efektiviteti i parashikimeve në situata të ngjashme në të ardhmen rritet ndjeshëm. Për shkak të kësaj taktike, ky bllok ka parashikime shumë më të sakta sesa ato të pasakta - procesorët modernë nga Intel dhe AMD përcaktojnë saktë drejtimin e tranzicionit të kushtëzuar në 95-97 raste. Natyrisht, falë kësaj, transportuesi rivendoset relativisht rrallë.
Epo, ju keni marrë një edukim të vogël për përpunuesit dhe tani ne mund të shohim se si funksionon gjithçka në realitet, sa efektive është kjo apo ajo arkitekturë dhe sa efektive janë njësitë ALU dhe FPU (dhe, natyrisht, njësitë e tyre ndihmëse). Për të qenë në gjendje të mbulojmë një gamë sa më të gjerë të bërthamave të procesorit dhe në të njëjtën kohë të minimizojmë ndikimin në rezultatet e testimit të pjesëve kaq të rëndësishme të CPU-ve moderne si cache, autobusi i procesorit dhe gjerësia e brezit të nënsistemit të kujtesës, ne iu drejtuam AIDA 64 Për më tepër, vetëm dy sintetike u zgjodhën nga testi i paketës - CPU Queen dhe FPU SinJulia. Pse ata? Përgjigja qëndron në vetë parimin e funksionimit të tyre dhe përputhjen e plotë me kërkesat e këtij testi. Për të kuptuar se si disa tipare arkitekturore të secilit test pasqyrohen në rezultatet e testit, le të hedhim një vështrim në përshkrimin zyrtar:
Mbretëresha e CPU-së
Një test i thjeshtë me numra të plotë. Rezultati varet kryesisht nga performanca e bllokut të operacioneve me numra të plotë, por është gjithashtu shumë i ndjeshëm ndaj efikasitetit të bllokut të parashikimit të degës, pasi kodi i tij përmban shumë degë të kushtëzuara.
Me shpejtësi të barabartë të orës së procesorit, avantazhi do t'i jepet modelit me një tubacion më të shkurtër dhe më pak gabime parashikimi. Në veçanti, me HyperThreading të çaktivizuar, procesori Pentium 4 në bërthamën Northwood do të marrë rezultate më të mira se modeli me bërthamën Prescott, pasi në rastin e parë përdoret një tubacion më i shkurtër me 20 faza, kundrejt një tubacioni me 31 faza në të dytin. .
Në të njëjtën kohë, aktivizimi i HyperThreading mund të ndryshojë balancën e fuqisë dhe të lejojë Prescott të fitojë. Për më tepër, performanca e procesorëve të familjes AMD K8 duhet të jetë më e lartë se ajo e modeleve të familjes K7, falë përdorimit të një njësie të përmirësuar të parashikimit të degëve.
Testi i CPU Queen përdor shtesat e transmetimit MMX dhe SSE, deri në versionin SSSE3. Zë më pak se 1 megabajt RAM. Mbështet HyperThreading, sistemet me shumë procesorë (SMP) dhe procesorë me shumë bërthama.
Zgjedhja e këtij testi u diktua, para së gjithash, nga aftësia për të zhdukur plotësisht ndikimin e nënsistemit të kujtesës dhe madhësisë së cache-ve në të gjitha nivelet në rezultat. Kjo do të thotë, merrni rezultatin e punës së ALU-së të mbështetur nga njësia e parashikimit të degëve. Testet e tjera nga paketa ALU, edhe pse pak, ende ndjejnë ndikimin e frekuencës dhe madhësisë së cache-ve, si dhe gjerësinë e brezit të autobusit të procesorit dhe autobusit të memories. Dhe në rastin tonë, kur krahasohen dhjetëra përpunues të gjeneratave të ndryshme, ndryshimi në performancën e këtyre nënsistemeve mund të arrijë disa rend të madhësisë. Për shembull, një tabelë përfshin: një procesor Pentium III që përdor memorie SDR-133 me një gjerësi autobusi memorie prej 64 bit, dhe një Core i7 që ka një autobus memorie 192-bit dhe që punon me memorie DDR3-1333.
Por mbështetja e HT në këtë rast nuk është shumë inkurajuese, pasi shumë procesorë në listë nuk e mbështesin atë, si shumë aplikacione reale. Megjithatë, ne thjesht do ta mbajmë parasysh këtë fakt kur krahasojmë drejtpërdrejt dy procesorë me dhe pa mbështetje HT.
FPU SinJulia
Test për llogaritjet me pikë lundruese me saktësi të shtuar (80 bit). Testi bazohet në llogaritjen e një kornize të një fraktali të modifikuar Julia. Kodi për këtë test është i shkruar në gjuhën e asamblesë, dhe për këtë arsye është i optimizuar në mënyrë të përkryer për procesorët Intel dhe AMD. Sidomos ato kernele që mund të përdorin udhëzime trigonometrike dhe eksponenciale x87.
Testi SinJulia FPU merr më pak se 1 megabajt RAM. Mbështet HyperThreading, sistemet me shumë procesorë (SMP) dhe procesorë me shumë bërthama.
Siç mund ta shihni, testi SinJulia FPU, si CPU Queen, është plotësisht i pavarur nga performanca e nënsistemit të kujtesës, si dhe nga frekuenca dhe madhësia e cache-ve të procesorit. Për më tepër, rezultati SinJulia do të jetë objektiv edhe kur krahasohet K6-III e lashtë dhe Phenom II moderne, për faktin se testi nuk përdor shtesa transmetimi si MMX dhe SSE. Epo, saktësia e lartë e llogaritjeve na lejon të nxjerrim përfundime që janë të përshtatshme për detyrat moderne që i janë caktuar CPU-së.
Zgjedhja e testeve është bërë, por tashmë dëgjoj zëra që kundërshtojnë përshtatshmërinë e rezultateve të krahasimit të përpunuesve të vjetër dhe të rinj. Një nga argumentet është çështja e krahasimit të procesorëve me numër të ndryshëm bërthamash dhe frekuenca të ndryshme. Pra, veçanërisht për objektivitetin e krahasimit, bazuar në rezultatet, kemi nxjerrë një koeficient të caktuar të performancës për çdo subjekt testues, i cili është llogaritur duke përdorur një formulë të thjeshtë:
rezultati i testit/numri i bërthamave/frekuenca
Duke i ndarë këto vlera për secilin procesor, kemi marrë rezultatin e një bërthame për cikël orësh. Duke marrë parasysh përshkrimin e testeve, është e nevojshme të bëhen disa ndryshime. Së pari: me mbështetjen e HyperThreading, procesori merr gjithmonë rezultate më të mira. Së dyti: procesorët që nuk mbështesin SSE do të tregojnë rezultate më të ulëta në testin ALU, domethënë, CPU Queen. Për fat të mirë, nuk ka shumë procesorë të tillë në listë, në fakt këta janë vetëm AMD K6-III.
Është gjithashtu e rëndësishme të mbani mend se pothuajse çdo procesor i testuar kishte motherboard-in e tij. Dhe çdo bord, në përputhje me rrethanat, ka gjeneratorin e vet të orës, i cili është në gjendje të mbivlerësojë dhe nënvlerësojë frekuencën e referencës së procesorit. Pasoja e këtij fakti është rezultate paksa të ndryshme për të njëjtin procesor në motherboard të ndryshëm. Duke pasur parasysh se ne nuk mund ta zhdukim këtë çështje, u vendos që të lëmë një gabim mjaft të madh në rezultate, gjë që përfundimisht e justifikoi veten, duke na lejuar të kombinojmë përpunuesit në grupe.
Dhe ky informacion ishte i nevojshëm për një ide adekuate të efektivitetit të një arkitekture të veçantë, dhe në disa raste, kernelit. Duke parë pak përpara, do të them se kjo metodë e llogaritjes e ka dëshmuar veten, duke demonstruar linearitet dhe varësi të lartë të rezultateve.
Tani le të flasim se si e testuam të gjithë këtë. Nëse e keni shikuar tashmë tabelën përmbledhëse, me siguri keni vënë re se në të ka 61 procesorë të gjeneratave të ndryshme. Natyrisht, jo të gjithë u testuan në laboratorin tonë vetëm pak më shumë se një e treta e përpunuesve të testuar në laboratorin tonë. Një pjesë e konsiderueshme e rezultateve janë marrë nga databaza e vetë programit AIDA 64 2.50, e cila ishte e vetmja paketë testimi në këtë krahasim. Natyrisht, ne nuk u mbështetëm verbërisht në rezultatet e paraqitura. Dhe ne kontrolluam dy herë rezultatet e bazës së të dhënave të tyre duke kryer testet tona për disa procesorë të ngjashëm. Rezultatet, duke marrë parasysh gabimin në frekuencën e referencës dhe, në përputhje me rrethanat, ndryshimin në frekuenca të tilla, ishin të këndshme, duke demonstruar pothuajse ngjashmëri të plotë. Prandaj, ne padyshim kombinuam rezultatet nga baza e të dhënave të programit me rezultatet tona në një tabelë.
Vlen gjithashtu të theksohet këtu se në versione të ndryshme të AIDA, llogaritja e rezultateve mund të mos jetë e njëjtë, dhe për këtë arsye ato nuk mund të krahasohen. Në rastin tonë, të gjitha rezultatet u morën vetëm në versionin 2.50.
Epo, është koha për të kaluar në ekzaminimin e rezultateve të testit, i cili doli të ishte shumë, shumë interesant. Është koha për të parë tabelën tonë kryesore, në të cilën do të gjeni karakteristikat e procesorit të rëndësishme në këtë test, dhe më e rëndësishmja, rezultatet e të dy testeve me të dhëna tashmë të shfaqura për performancën bazë për orë.

Duke marrë parasysh që efikasiteti i FPU-ve dhe ALU-ve mund të ndryshojë shumë, nuk duhet të habiteni në momentet kur i njëjti procesor ka performancë të shkëlqyer në të dhënat e numrave të plotë, por performon dukshëm më keq në të dhënat me pikë lundruese. Edhe pse, ndodh edhe anasjelltas. Para fillimit të tregimit, dua të theksoj se renditja në përshkrimin tim do të ndjekë një afat kohor, ndërsa në tabelë rezultatet janë renditur sipas rezultatit absolut të testit ALU.
Procesorët e parë dhe më të vjetër në këtë listë do të jenë modelet AMD K6-III në bërthamën Sharptooth dhe Pentium III në bërthamën Katmai. Këta procesorë kanë një tubacion mjaft të shkurtër për këto ditë - vetëm 12 faza për Intel dhe një minimum prej 6 fazash për AMD. Falë kësaj, kjo e fundit praktikisht nuk ka nevojë për një bllok parashikimi të degëve, pasi gabimet që lidhen me zgjedhjen e gabuar të rrugës nuk do të ndikojnë në rezultatin aq ndjeshëm sa në procesorin Pentium. Në fakt, ky procesor nuk e kishte këtë, por procesori Intel e kishte, dhe megjithëse sipas standardeve moderne efikasiteti i tij është i ulët, mekanizmat e analizës janë të njëjtë si në procesorët modernë. Si rezultat, AMD K6-III ka një rezultat më të lartë në testin ALU për shkak të tubacionit të shkurtër. Rezultati i tij është 2.03 njësi/cikël kundrejt 1.93 për konkurrentin e tij. Dhe kjo përkundër faktit se procesorët AMD të kësaj gjenerate nuk kishin mbështetje për shtesat e transmetimit SSE! Në të njëjtën kohë, në testin FPU, Pentium III është përpara, kryesisht falë njësisë së parashikimit të degëve, me një rezultat prej 0.164 njësi/cikël kundrejt 0.128 për përfaqësuesin e arkitekturës K6.

Pentium III u dallua nga efikasiteti i shkëlqyer. Vetëm Athlon mund të konkurronte me të në këtë parametër me sukses të ndryshëm
Bërthamat shumë të suksesshme Coppermine dhe Tualatin të procesorëve Pentium III që u shfaqën më vonë mbajtën të pandryshuar arkitekturën Katmai, dhe për këtë arsye rezultatet e dy procesorëve: Celeron 700 dhe Pentium III 1333 janë të ngjashme me ato që kemi parë tashmë. Por AMD, në kohën kur u lëshuan këta procesorë, tashmë e kishte braktisur arkitekturën K6, pasi për shkak të tubacionit të saj shumë të shkurtër nuk lejonte arritjen e frekuencave mbi 550 megaherz. Si rezultat, arkitektura e re K7 mori një tubacion më të gjatë me 10 faza dhe shumë veçori dhe ndryshime shtesë që sollën përmirësime të dukshme të performancës. Risia kryesore, dhe më e rëndësishmja në kuadër të këtij materiali, ishte shfaqja e një blloku të parashikimit të degëve. Sidoqoftë, produktet e reja, të cilat morën emrin e tyre Athlon, nuk arritën të tejkalojnë performancën e njësive ALU dhe procesorëve Pentium III. Por efikasiteti i FPU është rritur ndjeshëm: në këtë parametër, AMD K7 Athlon tejkaloi dukshëm K6 dhe u kap me konkurrentët e tij, duke demonstruar një rezultat prej 0.163 njësi / cikël. Por tubacioni më i gjatë uli ndjeshëm efikasitetin e njësisë ALU - në 1.58 njësi/cikël, domethënë me pothuajse 25 përqind në krahasim me K6. Megjithatë, kjo ishte e justifikuar, pasi që FPU në shumicën e aplikacioneve në atë kohë ishte më i rëndësishëm dhe frekuenca më e lartë që u arrit përfundimisht më shumë sesa mbulonte këto humbje.
Kalimi i AMD Athlon në bërthamën Thunderbird nuk ndryshoi në asnjë mënyrë ekuilibrin e fuqisë dhe efikasitetit për orë, sepse kjo bërthamë ka të njëjtën arkitekturë. Por, menjëherë pas tyre, në treg u shfaqën procesorët e parë Pentium 4 të ndërtuar mbi një arkitekturë krejtësisht të re NetBurst. Ndoshta nga pikëpamja e marketingut dhe e shitjeve, këta përpunues ishin një sukses i pakushtëzuar, por nga pikëpamja e inxhinierisë dhe efiçencës, nuk kishte arkitekturë më të keqe në histori.

Pentium 4 me bërthamë Willamette. Një nga procesorët e parë të bazuar në arkitekturën e pasuksesshme, por çuditërisht elastike, Netburst.
Arsyeja është kjo: në ndjekje të megahercit të madh që klientët dëshironin, inxhinierët e Intel ndërmorën një lëvizje jo të parëndësishme për të arritur frekuenca më të larta, ata e zgjatën ndjeshëm tubacionin - deri në 20 faza. Sigurisht, në garën për megahertz, ata u bënë menjëherë lider, por performanca për orë ra shumë dukshëm. Rezultati mesatar i procesorëve Pentium 4 në bërthamat Willamette dhe Northwood në testin ALU është 1.02, dhe në testin FPU është 0.108. Krahasoni me rezultatet e Pentium III - ndryshimi është kolosal! Për të tejkaluar procesorët e gjeneratës së mëparshme, Pentium 4 kishte nevojë për një frekuencë dukshëm më të lartë. Kjo është, në fakt, për të përftuar efikasitet të barabartë të njësive ALU me procesorin më të lartë të familjes Pentium III që funksionon me një frekuencë prej 1400 megahertz, bërthama Pentium 4 duhet të funksionojë në një frekuencë prej 2536 megahertz! Dhe për të arritur të njëjtin rezultat në testin FPU, ju nevojiten 2111 megaherz, që është pak më pak, por edhe aspak e vogël. Kjo do të thotë, nëse mesatarizojmë rezultatet, atëherë procesorët Pentium III 1400 dhe Pentium 4 2.4 do të jenë afërsisht të barabartë në efikasitet.
Në të njëjtën kohë, AMD nuk ndoqi Intel në frekuenca dhe, duke mbajtur arkitekturën K7 pothuajse të pandryshuar, lëshoi një linjë të procesorëve Athlon XP, procesorët e të cilëve nuk shënoheshin më nga frekuenca, por nga vlerësimet me një shenjë "plus". , i cili tregoi efikasitet në lidhje me procesorët Pentium 4 Kjo do të thotë, sipas tregtarëve të AMD, procesori Athlon XP 1800+ duhet të konkurrojë me Pentium 4 që funksionon me 1800 megahertz.
Le të kontrollojmë se sa adekuate ishte kjo qasje, duke pasur parasysh që efikasiteti i bërthamave Athlon XP është në nivelin 1.58 njësi/cikël në ALU dhe 0.163 njësi/cikël në FPU. Me frekuencën reale të modelit 1800+ të barabartë me 1533 megahertz, rezultati është 2422 njësi në CPU-në Queen dhe 250 në FPU SinJulia. Në të njëjtën kohë, rezultati i një Pentium 4 me një frekuencë prej 1.8 gigahertz do të jetë përkatësisht 1908 dhe 195 njësi. Duket se vlerësimi është madje i nënvlerësuar. Edhe pse nuk duhet të harrojmë se performanca në aplikacionet reale mund të jetë paksa e ndryshme nëse marrim parasysh karakteristikat e tjera të procesorit, si cache, autobusët dhe gjëra të tjera.
Çuditërisht, përvoja e hidhur nuk u mësoi inxhinierëve të Intel asgjë të mirë, dhe përsëri, të përballur me pamundësinë e rritjes së frekuencës, ata përsëri shkojnë për të rritur gjatësinë e tubacionit. Për më tepër, jo me disa faza, por në mënyrë të konsiderueshme - nëse bërthama e Northwood kishte 20 faza, atëherë në Prescott kishte 31 prej tyre dhe ky nuk është vetëm një transportues i gjatë. Po, sigurisht, falë këtij ndryshimi, pragu për frekuencën maksimale të orës së bërthamave të reja ishte më i lartë, por edhe shpërndarja e nxehtësisë ishte më e lartë.

Bërthama Prescott ishte një përkeqësim i mëtejshëm i arkitekturës Netburst në ndjekje të megahertzit të lartë. Bërthama më e paefektshme Intel ndonjëherë.
Megjithatë, ndryshimi më i rëndësishëm, të cilin jo të gjithë ishin në gjendje ta vlerësonin, ishte një rënie e ndjeshme e efikasitetit në krahasim me paraardhësin e tij, dhe megjithëse ardhja e teknologjisë HyperThreading në njëfarë kuptimi e shpëtoi situatën, procesorët që nuk e përdorin atë treguan thjesht një tmerr të tmerrshëm. niveli i efikasitetit. Gjeni në tabelë procesorët Pentium D 820 dhe 925, si dhe Celeron D 326 dhe do të kuptoni se për çfarë po flas. Rezultati për cikël i demonstruar në testin CPU Queen ishte 0,75 njësi modeste dhe FPU SinJulia vlerësoi efikasitetin e arkitekturës së përditësuar NetBurst në vetëm 0,081 njësi. Rënia e performancës në lidhje me bërthamat Willamette/Northwood ishte afërsisht 30 përqind në ALU dhe deri në 40 përqind në FPU.
Krahasimi i Prescott-256 dhe Smithfield me procesorët AMD K8 është krejtësisht i kotë. Meqenëse arkitektura e re mori vetëm një tubacion me dy faza më të gjatë se K7, por në të njëjtën kohë fitoi një njësi parashikimi të degëve të përmirësuar ndjeshëm dhe më efikase. Dhe si rezultat, bërthamat e bazuara në arkitekturën e re demonstrojnë efikasitet pak më të lartë ALU dhe FPU. Rezultati mesatar i testit të CPU Queen u rrit në 1.74 njësi dhe SinJulia FPU mbeti në nivelin e paraardhësit të tij. Siç mund ta shihni, jo më kot procesorët Athlon 64 dhe Sempron dikur vlerësoheshin shumë nga lojtarët - efikasiteti i tyre është shumë i lartë, më shumë se dy herë më i lartë se ai i Pentium 4 i shumëpërfolur me bërthama Prescott dhe Smithfield, i cili në shumicën e aplikacioneve nuk u ndihmuan nga performanca më e lartë në kohë frekuencë, as sasia e madhe e cache-it të nivelit të dytë.

Një zgjidhje shumë e suksesshme nga AMD është Athlon 64. Krahasuar me Pentium 4, këta procesorë u dalluan për konsumin e ulët të energjisë dhe efikasitetin e shkëlqyer.
Sidoqoftë, në këtë fazë ia vlen të kujtojmë se ishte në thelbin Prescott që u shfaq teknologjia HyperThreading. Sigurisht, nuk u shfaq për shkak të një jete të mirë dhe ishte një përpjekje e pasuksesshme për të maskuar të metat e një rripi të gjatë transportues. Ishte falë kësaj teknologjie, megjithëse ende e papërsosur në atë kohë, që inxhinierët arritën të rrafshonin zgjatjen e transportuesit. Për shembull, procesori Pentium 4 2800E i bazuar në bërthamën Prescott dhe HT mbështetës demonstroi efikasitet të ngjashëm me bërthamat me një tubacion 20 fazash, por pa HT. Megjithatë, nuk ishte e mundur të arrihet një rritje e efikasitetit nga mbështetja HyperThreading për bërthamat Willamette/Northwood, siç dëshmohet nga rezultatet e procesorit të rrallë Pentium 4 3.46 GHz Extreme Edition, i cili bazohet në bërthamën Gallatin (analog me Northwood, por me një cache 2 MB L3) dhe mbështet këtë teknologji.
Pak më vonë, tashmë në fund të epokës NetBurst, inxhinierët e Intel arritën të përmirësojnë ndjeshëm HyperThreading dhe të arrijnë një rritje të mirë të efikasitetit të njësisë së llogaritjes së pikës lundruese. Kushtojini vëmendje versionit më të shpejtë në linjë, Pentium 4 me një bërthamë 3,73 GHz Extreme Edition dhe Pentium 955 Extreme Edition me dy bërthama. Efikasiteti i tyre i FPU është tashmë 0,138 njësi, megjithëse performanca e ALU është në të njëjtin nivel. Sidoqoftë, edhe falë kësaj, nuk ishte e mundur të tejkalonte konkurrentët e saj kryesorë - AMD Athlon 64 X2, pavarësisht nga fakti se këta të fundit funksionojnë me një frekuencë më të ulët të orës dhe nuk mbështesin HT.
Shikoni tabelën - asnjë nga procesorët e arkitekturës NetBurst nuk mund të konkurrojë me Athlon 64 X2 5200+, e lëre më AMD Athlon 64 6400+ më të mirë në atë kohë. Sidoqoftë, Intel e kuptoi shumë kohë më parë se ndjekja e "gigahertzit të madh" ishte një gabim, dhe për këtë arsye po përgatiste arkitekturën më të fundit, e cila do të ishte jo më pak e suksesshme në aspektin e marketingut se Pentium 4, por shumë më efikase.

Athlon 64 X2 është ndoshta procesori i fundit deri më sot që mund t'i tejkalojë procesorët e nivelit të lartë Intel. Sidoqoftë, nuk ishte e vështirë për të mposhtur Pentium D joefikas dhe të nxehtë.
Ne po flasim, natyrisht, për Core. Gjatë zhvillimit të kësaj arkitekture, inxhinierët e Intel-it u kthyen në një tubacion me vetëm 14 faza, domethënë e shkurtuan atë me më shumë se gjysmën në krahasim me përfaqësuesit e fundit të NetBurst. Natyrisht, në kushte të tilla, nuk flitej për arritjen e 4 gigahertz, por tashmë përfaqësuesit e parë të familjes së re, pavarësisht frekuencës së ulët, demonstruan performancën më të lartë. Të dy procesorët e kësaj gjenerate - Pentium M 730 në bërthamën Dothan dhe Core Duo T2500 në bërthamën Yonah treguan rezultate për orë që ishin superiore edhe ndaj Pentium III, dhe dukshëm më të larta se ato të familjes konkurruese AMD K8.
Arkitektura, e testuar në zgjidhjet celulare, erdhi në tregun e desktopit në një formë pak të modifikuar në formën e procesorëve Core 2 Duo dhe Pentium Dual Core. Në kohën e lëshimit, ata nuk mund të mburreshin me frekuenca të larta, por në të njëjtën kohë ata demonstruan efikasitetin më të lartë dhe, si rezultat, performancën, edhe përkundër mungesës së mbështetjes HyperThreading! Natyrisht, blloku i parashikimit të degëve i përmirësuar ndjeshëm gjithashtu funksionoi për këtë. Shikoni rezultatet. Në testin e CPU Queen, efikasiteti mesatar i bërthamës Conroe dhe derivateve të tij u rrit në një nivel prej më shumë se dy njësi për orë dhe arriti një mesatare prej 2.13. Në testin FPU SinJulia rezultati është gjithashtu shumë i mirë - 0,175. Kjo, edhe pse jo shumë, është më shumë se ajo e procesorëve të arkitekturës Core të gjeneratës së parë dhe shumë më e lartë se ajo e AMD K8, me të cilën Pentium 4 luftoi kaq gjatë dhe pa sukses.

Arkitektura Core 2 që zëvendësoi NetBurst tregoi se Intel mund të bëjë procesorë të shpejtë dhe të lezetshëm që janë shumë efikas.
Efikasiteti më i lartë i bërthamave u vërtetua edhe një herë nga Celeron me një bërthamë, i lëshuar pak më vonë, i cili, në një frekuencë modeste, falë bërthamës Conroe-L, tregoi performancë në nivelin e paraardhësve të tij që vepronin me dyfishin e frekuencës. . Dhe kjo, ki parasysh, është me të njëjtin bërthamë. Në përgjithësi, kjo arkitekturë është dëshmuar të jetë më efikasja dhe ka detyruar AMD të përpiqet të arrijë rivalët e saj.
Dhe këtu filluan problemet e AMD. Tani ata nuk kishin një avantazh në efikasitetin bazë, dhe në vend që ta rindërtonin plotësisht atë, inxhinierët, kur krijuan gjeneratën K10 dhe, në përputhje me rrethanat, përpunuesit e quajtur Phenom dhe Athlon, filluan të rrisin numrin e bërthamave dhe memorieve të brendshme. Performanca e përgjithshme e këtyre zgjidhjeve, natyrisht, është rritur, por ndryshimet e bëra kanë pak efekt në efikasitetin. Performanca e ALU u rrit pak, me sa duket për shkak të njësisë së parashikimit të degëve të përmirësuar edhe një herë, por efikasiteti i FPU mbeti plotësisht i pandryshuar - me karakteristika të tilla ishte e mundur të konkurrohej me Core 2 vetëm për shkak të një numri më të madh bërthamash ose një frekuencë më të lartë. Me këtë të fundit, procesorët e gjeneratës K10 patën, siç e mbani mend, probleme shumë serioze.

Phenom është padyshim një procesor i pasuksesshëm. Efikasiteti i tij nuk arriti në Core 2, dhe kishte probleme serioze me frekuencat.
Si rezultat, Phenom nuk u bë kurrë një konkurrent i procesorëve Core 2 Duo dhe Core 2 Quad. Sidoqoftë, problemi me frekuencat u zgjidh shpejt, dhe procesorët e rinj Phenom II dhe Athlon II të arkitekturës K10.5 ishin gati të konkurronin me zgjidhjet nga Intel në këtë drejtim. Por efikasiteti në gjeneratën e re mbeti në të njëjtin nivel, dhe për këtë arsye zgjidhjet AMD nuk mund të konkurronin me konkurrentët në frekuenca të barabarta. Përveç kësaj, kur kaloi në teknologjinë e procesit 45 nanometër, Intel përsëri bëri pak magji në arkitekturë dhe arriti një rritje tjetër të efikasitetit të njësisë FPU, në nivelin 0,185 njësi/cikël.
Pavarësisht epërsisë së rehatshme, një armë e re perfekte ishte krijuar tashmë në punëtoritë dhe laboratorët e Intel, duke zhvilluar arkitekturën Core, e cila pa dritën e ditës në procesorët Core i3, i5 dhe i7 me emrin e përgjithshëm Nehalem. Ndryshimet e radhës në blloqe dhe përmirësimi i të gjithë parametrave çuan në rezultate të shkëlqyera. Shikoni performancën e Core i5-750: efikasiteti i ALU mbeti pothuajse në nivelin e Core 2, por në të njëjtën kohë, performanca e bllokut më të rëndësishëm të operacioneve me numër të plotë për momentin u rrit ndjeshëm - deri në 0.225 njësi për orë!
Por, përveç përmirësimeve arkitekturore, Intel po përgatiste një superarmë tjetër - teknologjinë e përsosur HyperThreading. Përdorimi i tij ka bërë të mundur marrjen e një efikasiteti thjesht fantastik. Kjo teknologji, e optimizuar siç duhet, dha një efekt të madh dhe pothuajse një herë e gjysmë rritje të efikasitetit! 3.05 në ALU dhe 0.36 në FPU janë thjesht rezultate të shkëlqyera. Megjithatë, edhe pa mbështetjen e kësaj teknologjie, procesorët e bazuar në arkitekturën Nehalem rezultuan të ishin më efikas se paraardhësit dhe konkurrentët e tyre.

Nehalen ishte arkitektura e parë Intel në të cilën vëmendje maksimale iu kushtua efikasitetit bazë. Rezultati ishte i shkëlqyer. Pasardhësit në formën e Sandy Bridge dhe Ivy Bridge treguan se kishte ende potencial.
Dy gjeneratat pasuese nga Intel - procesorë të bazuar në bërthamat Sandy Bridge dhe Ivy Bridge - demonstruan gjithashtu performancë më të lartë jo vetëm për shkak të rritjes së frekuencës. Ndryshimet e vogla në bërthama bënë të mundur rritjen e vazhdueshme të performancës së bllokut të operacioneve me numër të plotë me 0,25 njësi/cikël në çdo gjeneratë, si me dhe pa HyperThreading. Por nuk ka asnjë ndryshim në efikasitetin e FPU. Megjithatë, edhe pa përmirësime, ky tregues është shumë i mirë. Duke pasur parasysh trendin, mund të presim një rritje tjetër të efikasitetit kur të shfaqet gjenerata e ardhshme e procesorëve Intel.
AMD mund të ëndërrojë vetëm për një efikasitet të tillë. Megjithatë, ata nuk janë ulur ende, duke u përpjekur të përmirësojnë performancën e procesorëve të tyre. Në veçanti, procesorët Llano të bazuara në bërthamat e arkitekturës K10.5 demonstruan efikasitet pak më të lartë ALU sesa Phenom dhe Athlon më të fundit. Kryesisht falë një njësie të përmirësuar të parashikimit të degëve, ndërsa efikasiteti i FPU mbeti në të njëjtin nivel siç u demonstrua nga të gjithë procesorët e mëparshëm AMD që nga familja e parë Athlon K7.

Përfaqësuesi më i fundit i familjes AMD, i cili filloi në gjeneratën K7, është Liano APU. Fatkeqësisht, ai gjithashtu nuk shkëlqen me efikasitet në krahasim me procesorët më të fundit Intel
Sidoqoftë, edhe Llano mund të konsiderohet një zgjidhje e vjetëruar, pasi e ardhmja e afërt e procesorëve AMD do të shoqërohet me procesorë të arkitekturës krejtësisht të re Bulldozer, e cila u prezantua në procesorët AMD FX dhe derivatet e tij. Ishin këta procesorë, të cilët rezultuan aspak të padiskutueshëm, që na vunë në një rrugë pa krye kur llogaritim efikasitetin e bërthamave. Dhe gjithçka sepse parimi i organizimit bërthamor në to është shumë i ndërlikuar. Në veçanti, procesori FX-8150 ka katër module me dy bërthama dhe kompania e deklaron atë të jetë me tetë bërthama. Për të ndëshkuar kompaninë për këtë, ishte plotësisht e mundur të llogaritet efikasiteti i saj bazuar në tetë bërthama, por kjo do të ishte teknikisht e pasaktë, dhe rezultati do të ishte në nivelin e procesorëve Intel bazuar në arkitekturën NetBurst. Prandaj, u vendos që të llogaritet efikasiteti jo për bërthamë, por për modul, gjë që është mjaft e justifikuar, duke qenë se çdo modul ka vetëm një njësi llogaritëse të pikës lundruese.

AMD FX në arkitekturën Buldozer tregoi një rritje të dukshme të efikasitetit, por arkitektura komplekse ende nuk është zbuluar. Dhe ndoshta ai nuk do ta zbulojë më.
Me ALU-të, gjithçka është më e ndërlikuar - në të vërtetë ka tetë njësi të tilla në një procesor me katër module, por ato nuk mund të punojnë paralelisht me efikasitet të mjaftueshëm për shkak të veçorive të menaxherit të detyrave në Windows 7 dhe sistemeve operative të mëparshme nga Microsoft. Prandaj, u vendos që të llogaritet efikasiteti i ALU bazuar në numrin e moduleve. Ky vendim është i diskutueshëm dhe unë nuk do të insistoj në objektivitetin e këtij rezultati. Dhe rezultatet, nga rruga, doli të ishin relativisht të mira. Në lidhje me paraardhësit, natyrisht. Në veçanti, për sa i përket efikasitetit të rezultatit të diskutueshëm ALU, procesorët e arkitekturës Bulldozer treguan një rezultat prej 2.2 njësi/cikël, që është dukshëm më i lartë se K10.5, Llano dhe madje pak më shumë se Core 2, megjithëse para Sandy Bridge, madje. pa mbështetje Hyper Threading është ende shumë larg. Efikasiteti i FPU (ky rezultat mund t'i besohet plotësisht) gjithashtu tejkaloi ndjeshëm të gjitha zgjidhjet e mëparshme AMD dhe doli të ishte pikërisht midis arkitekturës së hershme dhe të vonë Core 2.
Bazuar në këto rezultate, mund të konkludojmë se procesorët e arkitekturës Bulldozer nuk janë definitivisht konkurrentë të procesorëve Intel duke filluar me Nehalem, por ata mund të luftojnë Core 2 në mënyrë shumë efektive dhe madje t'i tejkalojnë ato në frekuenca të barabarta. Jo përfundimi më pozitiv për të Gjelbrit.
Për lehtësinë tuaj, ne kemi përmbledhur të gjitha rezultatet në një tabelë me tregues të efikasitetit mesatar për bërthama të ndryshme.


Në këtë pikë në studimin tonë mund të vendosim një elipsë. Jo, jo pikë, sepse ky material nuk pretendon të jetë absolutisht global dhe siç thashë në fillim të materialit, nuk merr parasysh efikasitetin e shumë blloqeve të procesorit shumë të rëndësishëm. Sidoqoftë, nuk ka procesorë të shpejtë pa ALU dhe FPU të fuqishme, dhe ky material konfirmoi plotësisht këtë postulat. Historia e ka vënë çdo gjë në vendin e vet dhe nga lartësia e viteve të shkuara mund të vendosësh pulla dhe të vësh në dukje gabimet lehtësisht dhe natyrshëm. Por janë pikërisht këto gabime që janë shoqëruesi i vazhdueshëm i progresit, të cilat, pavarësisht nga të gjitha degët pa rrugëdalje, na çojnë në mënyrë të qëndrueshme drejt një të ardhmeje të lumtur dixhitale.
Materiale të ngjashme:Bashkëprocesorët e familjes Intel x86
Për procesorët e familjes x86, njësia me pikë lundruese është ndarë në një çip të veçantë të quajtur bashkëprocesor matematik. U sigurua një lidhës i veçantë për instalimin e bashkëprocesorit në bordin e kompjuterit.
Bashkëprocesori nuk është një procesor i plotë, pasi nuk di të bëjë shumë nga operacionet e nevojshme për këtë (për shembull, nuk di të punojë me një program dhe të llogarisë adresat e kujtesës), duke qenë vetëm një shtojcë e procesori qendror.
Një nga skemat e ndërveprimit midis procesorit qendror dhe bashkëprocesorit, e përdorur, veçanërisht, në bashkëprocesorët x86, zbatohet si më poshtë:
Platforma të tjera
Po kështu, pllakat amë të PC-ve të ndërtuara në procesorë Motorola përmbanin një bashkëprocesor matematikor përpara zhvillimit të procesorit MC68040 nga ajo kompani (në të cilin ishte i integruar bashkëprocesori). Në mënyrë tipike, një bashkëprocesor 68881 16 MHz ose 68882 25 MHz përdorej si FPU. Pothuajse çdo procesor modern ka një bashkëprocesor të integruar.
Weitek gjithashtu prodhoi bashkëprocesorë matematikorë për platforma dhe MIPS.
Pajisja FPU
Regjistrat FPU organizohen jo si një grup, si në disa arkitektura të tjera, por si një pirg regjistrash. Pra FPU është kalkulator i stivës, duke punuar në parimin e shënimit të kundërt polak. Kjo do të thotë që udhëzimet përdorin gjithmonë vlerën e sipërme në pirg për të kryer operacione, dhe aksesi në vlerat e tjera të ruajtura zakonisht arrihet përmes manipulimit të stivës. Megjithatë, kur punoni me pjesën e sipërme të stivit, elementë të tjerë të stivit mund të përdoren në të njëjtën kohë, për të hyrë në cilin adresim të drejtpërdrejtë në lidhje me pjesën e sipërme të stivit përdoret. Operacionet mund të përdorin gjithashtu vlera të ruajtura në RAM. Sekuenca e zakonshme e veprimeve është si më poshtë. Përpara operacionit, argumentet shtyhen në pirgun LIFO; Kur të kryhet operacioni, numri i kërkuar i argumenteve hiqet nga pirgu. Rezultati i operacionit vendoset në pirg, ku mund të përdoret në llogaritjet e mëtejshme ose të hiqet nga pirgu për t'u shkruar në kujtesë. Megjithëse organizimi i grumbulluar i regjistrave të FPU-së është i përshtatshëm për programuesit, ai e ndërlikon detyrën e përpiluesve për të ndërtuar kode efikase.
Veçoritë e përdorimit
Pas publikimit të 3DNow! nga AMD dhe më pas SSE, duke filluar me procesorët Pentium III të Intel, llogaritjet me saktësi të vetme u bënë të mundura pa ndihmën e udhëzimeve të FPU-së dhe me performancë të rritur. Zgjerimi SSE2 dhe shtesat e mëvonshme të grupit të udhëzimeve siguruan gjithashtu llogaritje të shpejta me saktësi të dyfishtë (shih standardin IEEE-754). Në këtë drejtim, në kompjuterët modernë nevoja për komanda nga një bashkëprocesor matematikor klasik është ulur ndjeshëm. Megjithatë, ato mbështeten ende në të gjithë procesorët x86 në prodhim për përputhshmëri me aplikacionet më të vjetra dhe për aplikacione që kërkojnë konvertime BCD ose llogaritje me saktësi të zgjeruar (ku saktësia e dyfishtë nuk është e mjaftueshme). Aktualisht duke përdorur komanda x87 mbetet mënyra më efikase për të kryer llogaritje të tilla.
Formatet e të dhënave
Brenda FPU-së, numrat ruhen në formatin me pikë lundruese 80-bit (precizion të zgjeruar), dhe sa vijon mund të përdoret për të shkruar ose lexuar nga memoria:
- Numrat realë në tre formate: të shkurtër (32 bit), të gjatë (64 bit) dhe të zgjeruar (80 bit).
- Numrat e plotë binarë në tre formate: 16, 32 dhe 64 bit.
- Numrat dhjetorë të paketuar me numra të plotë (BCD) - gjatësia maksimale e numrit është 18 shifra dhjetore të paketuara (72 bit).
FPU gjithashtu mbështet vlera të veçanta numerike:
- Numrat realë të çnormalizuar janë numra, vlera absolute e të cilëve është më e vogël se numri minimal i normalizuar. Kur një vlerë e tillë formohet në një regjistër të caktuar, një vlerë e veçantë 10 formohet në etiketën e regjistrit TWR që korrespondon me këtë regjistër Një shenjë e një numri të çnormalizuar në paraqitjen e tij binar është fusha e rendit zero.
- Pafundësia (pozitive dhe negative), ndodh kur një vlerë jo zero pjesëtohet me zero, si dhe tejmbushet. Kur një vlerë e tillë formohet në një regjistër të caktuar të pirgut, një vlerë e veçantë 10 formohet në etiketën e regjistrit TWR që korrespondon me këtë regjistër.
- jo-numër (anglisht jo-a-numër (NaN)). Ekzistojnë dy lloje të jo-numrave:
- SNaN (Signaling Non a Number) - sinjal jo-numra. Bashkëprocesori reagon ndaj shfaqjes së këtij numri në regjistrin e stivit duke ngritur një përjashtim të pavlefshëm operacioni. Bashkëprocesori nuk gjeneron numra sinjalesh. Programuesit formojnë numra të tillë qëllimisht në mënyrë që të bëjnë një përjashtim në situatën e duhur.
- QNaN (Quiet Non a Number) - jo-numra të qetë (të qetë). Bashkëprocesori mund të gjenerojë jo-numra të qetë në përgjigje të disa përjashtimeve, siç është numri real i pasigurisë.
- Zero (pozitive dhe negative). Edhe pse zero mund të konsiderohet një vlerë e veçantë për sa i përket formatit të pikës lundruese, është gjithashtu një rast i veçantë i një numri të çnormalizuar.
- Pasiguritë dhe formatet e pambështetura. Ka shumë grupe bitësh që mund të paraqiten në formatin e zgjeruar të numrave realë. Për shumicën e vlerave të tyre, krijohet një përjashtim i pavlefshëm i operacionit.
Regjistrat
Ekzistojnë tre grupe regjistrash në FPU:
- Stacki i procesorit: regjistrat R0..R7. Dimensioni i çdo regjistri: 80 bit.
- Regjistrat e shërbimit
- Regjistri i statusit të procesorit SWR (Status Word Register) - informacion në lidhje me gjendjen aktuale të bashkëprocesorit. Dimensioni: 16 bit.
- Regjistri i kontrollit të bashkëprocesorit CWR (Control Word Register) - kontrolli i mënyrave të funksionimit të bashkëprocesorit. Dimensioni: 16 bit.
- Regjistrimi i etiketave të fjalëve TWR (Tags Word Register) - kontroll mbi regjistrat R0..R7 (për shembull, për të përcaktuar aftësinë e shkrimit). Dimensioni: 16 bit.
- Regjistrat e treguesve
- Treguesi i të dhënave DPR (Data Point Register). Dimensioni: 48 bit.
- Indeksi i komandës IPR (Instruction Point Register). Dimensioni: 48 bit.
Sistemi i instruksionit të bashkëprocesorit
Sistemi përfshin rreth 80 komanda. Klasifikimi i tyre:
- Komandat e transferimit të të dhënave
- Të dhëna reale
- Të dhëna të plota
- Të dhëna dhjetore
- Ngarkimi i konstantave (0, 1, Pi, log 2 (10), log 2 (e), log (2), ln (2))
- Shkëmbim
- Përcjellja e kushtëzuar (Pentium II/III)
- Komandat e krahasimit të të dhënave
- Të dhëna reale
- Të dhëna të plota
- Analiza
- Nga e para
- Krahasimi i kushtëzuar (Pentium II/III)
- Komandat aritmetike
- Të dhëna reale: mbledhje, zbritje, shumëzim, pjesëtim
- Të dhënat e numrave të plotë: mbledhje, zbritje, shumëzim, pjesëtim
- Komandat ndihmëse aritmetike (rrënja katrore, moduli, ndryshimi i shenjës, nxjerrja e eksponentit dhe mantisës)
- Komandat transhendente
- Trigonometria: sinus, kosinus, tangjent, arktangjent
- Llogaritja e logaritmeve dhe fuqive
- Komandat e kontrollit
- Inicializimi i bashkëprocesorit
- Puna me mjedisin
- Duke punuar me pirg
- Ndërrimi i mënyrave
AIDA64 përmban disa teste që mund të përdoren për të vlerësuar performancën e pjesëve individuale të pajisjeve ose të sistemit në tërësi. Këto janë teste sintetike, që do të thotë se mund të vlerësojnë performancën maksimale teorike të një sistemi. Testet e xhiros së memories, CPU ose FPU bazohen në motorin e testimit me shumë fije AIDA64, i cili mbështet deri në 640 fije të përpunimit të njëkohshëm dhe 10 grupe procesorësh (që nga AIDA64 Business 4.00). Ky mekanizëm ofron mbështetje të plotë për multiprocesorët (SMP), teknologjitë me shumë bërthama dhe hiperthreading.
Testimi i performancës së cache dhe diskut
AIDA64 ofron gjithashtu teste të veçanta për të vlerësuar performancën e leximit, shkrimit dhe kopjimit, si dhe cache-in e CPU-së dhe vonesën e kujtesës së sistemit. Ekziston gjithashtu një modul i veçantë testimi për vlerësimin e performancës së pajisjeve të ruajtjes, duke përfshirë disqet e ngurtë (S)ATA ose SCSI, grupet RAID, disqet optike, disqet SSD, disqet USB dhe kartat e kujtesës.
Testimi i performancës GPGPU
Ky panel testimi, i cili mund të aksesohet në seksionin e menysë Veglat | GPGPU Benchmark, ofron një grup testesh të performancës OpenCL GPGPU. Ato janë krijuar për të vlerësuar performancën e llogaritjes GPGPU duke përdorur ngarkesa të ndryshme pune OpenCL. Çdo test individual mund të ekzekutohet në një maksimum prej 16 GPU, duke përfshirë procesorë AMD, Intel dhe NVIDIA, ose kombinime të tyre. Sigurisht, konfigurimet CrossFire dhe SLI mbështeten plotësisht, si dhe dGPU dhe APU. Në përgjithësi, ky funksion ju lejon të testoni performancën e pothuajse çdo pajisjeje kompjuterike që përfaqësohet si një GPU midis pajisjeve OpenCL.

Përveç testeve gjithëpërfshirëse të performancës, AIDA64 ofron mikro-teste speciale - ato mund të gjenden në seksionin "Testet" në menunë "Faqja". Falë një baze të dhënash referencë gjithëpërfshirëse të rezultateve, rezultatet e testit të performancës mund të krahasohen me rezultate të ngjashme nga konfigurime të tjera. Mikrotestet e mëposhtme janë aktualisht në dispozicion:
Testimi i performancës së kujtesës
Testet e performancës së kujtesës vlerësojnë kapacitetin maksimal të mundshëm gjatë kryerjes së operacioneve të caktuara (lexim, shkrim, kopjim). Ato janë shkruar në gjuhën e asamblesë dhe janë optimizuar maksimalisht për të gjitha variantet e njohura të bërthamave të procesorëve AMD, Intel dhe VIA duke përdorur shtesat e duhura të grupit të udhëzimeve x86/x64, x87, MMX, MMX+, 3DNow!, SSE, SSE2, SSE4.1, AVX dhe AVX2.
Testi i vonesës së kujtesës vlerëson vonesën tipike kur CPU lexon të dhëna nga memoria e sistemit. Vonesa e memories është koha për të siguruar të dhëna në regjistrin aritmetik të numrave të plotë të CPU-së pas lëshimit të një komande leximi.
Mbretëresha e CPU-së

Ky test i thjeshtë me numër të plotë vlerëson aftësitë e parashikimit të degës së CPU dhe parashikimit të gabuar të degëve. Ai llogarit zgjidhjet e një enigme klasike me tetë mbretëresha të vendosura në një tabelë shahu 10x10. Teorikisht, me të njëjtën shpejtësi të orës, një procesor me një tubacion më të shkurtër dhe më pak shpenzime në rast të një supozimi të pasaktë të degës mund të tregojë rezultate më të mira testimi. Për shembull, nëse çaktivizon hiperthreading, procesorët Pentium 4 me bazë në Intel Northwood do të kenë rezultate më të larta se CPU-të Intel Prescott sepse i pari ka një tubacion me 20 faza ndërsa i dyti ka një tubacion 31 fazash. CPU Queen përdor optimizimet e numrave të plotë MMX, SSE2 dhe SSSE3.
CPU PhotoWorxx

Ky test numër i plotë vlerëson performancën e CPU-së duke përdorur disa algoritme të përpunimit të fotografive 2D. Ai kryen detyrat e mëposhtme me imazhe mjaft të mëdha RGB:
- mbushja e figurës me pikselë të një ngjyre të zgjedhur rastësisht;
- rrotulloni imazhin 90 gradë në të kundërt të akrepave të orës;
- rrotulloni imazhin 180 gradë;
- diferencimi i imazhit;
- konvertimi i hapësirës së ngjyrave (përdoret, për shembull, në konvertimin JPEG).
Testi është menduar kryesisht për blloqet e kryerjes së operacioneve aritmetike me numra të plotë të arkitekturës SIMD të procesorit qendror dhe nënsistemeve të kujtesës. Testi i CPU-së PhotoWorxx përdor shtesat përkatëse të grupit të instruksioneve x87, MMX, MMX+, 3DNow!, 3DNow!+, SSE, SSE2, SSSE3, SSE4.1, SSE4A, AVX, AVX2 dhe mbështet NUMA, hiperthreading, multiprocesorë. dhe me shumë bërthama (CMP).
CPU ZLib
Ky pikë referimi me numër të plotë vlerëson performancën e kombinuar të CPU-së dhe nënsistemit të kujtesës duke përdorur bibliotekën e kompresimit të të dhënave falas ZLib. CPU ZLib përdor vetëm udhëzime bazë x86, por mbështet hiperthreading, multiprocessing (SMP) dhe multi-core (CMP).
CPU AES
Ky test numër i plotë vlerëson performancën e CPU-së kur kryen kriptim AES. Në enkriptim, AES është një algoritëm simetrik i shifrimit të bllokut. Sot, AES përdoret në disa mjete kompresimi si 7z, RAR, WinZip, si dhe në programet e enkriptimit BitLocker, FileVault (Mac OS X), TrueCrypt. CPU AES përdor udhëzimet e duhura x86, MMX dhe SSE4.1 dhe është i përshpejtuar në harduer në procesorët VIA C3, VIA C7, VIA Nano dhe VIA QuadCore që mbështesin motorin e sigurisë VIA PadLock, si dhe në procesorët që mbështesin Intel AES Zgjerimi i grupit të udhëzimeve NI. Ky test mbështet hiperthreading, multiprocessors (SMP) dhe multicores (CMP).
Hash i CPU-së
Ky test numër i plotë vlerëson performancën e CPU-së kur ekzekuton algoritmin e memorizimit SHA1 sipas Standardit Federal të Përpunimit të Informacionit 180-4. Kodi për këtë test është i shkruar në gjuhën e asamblesë dhe është optimizuar për bërthamat më të njohura të procesorëve AMD, Intel dhe VIA duke përdorur shtesat përkatëse të grupit të udhëzimeve MMX, MMX+/SSE, SSE2, SSSE3, AVX, AVX2, XOP, BMI dhe BMI2. Testi Hash i CPU-së është i përshpejtuar në harduer në procesorët VIA C7, VIA Nano dhe VIA QuadCore që mbështesin teknologjinë VIA PadLock Security Engine.
FPU VP8
Ky test mat performancën e kompresimit të videove të versionit 1.1.0 të kodikut VP8 (WebM) të Google. Kodimi ndodh në 1 kalim të një transmetimi video me një rezolucion 1280x720 ("HD gati") dhe një shpejtësi prej 8192 kbps në cilësimet maksimale të cilësisë. Përmbajtja e kornizës gjenerohet nga moduli fraktal Julia FPU. Kodi i provës përdor shtesa dhe grupe instruksionesh MMX, SSE2, SSSE3 ose SSE4.1, dhe gjithashtu mbështet hiperthreading, multiprocesorët (SMP) dhe multicores (CMP).
FPU Julia

Ky pikë referimi vlerëson performancën me një pikë lundruese me saktësi të vetme (precizion 32-bit) duke llogaritur fragmente të shumta fraktale Julia. Kodi për këtë test është i shkruar në gjuhën e asamblesë dhe është optimizuar për bërthamat më të njohura të procesorëve AMD, Intel dhe VIA duke përdorur shtesat e përshtatshme të grupit të instruksioneve x87, 3DNow!, 3DNow!+, SSE, AVX, AVX2, FMA dhe FMA4. . FPU Julia mbështet hiperthreading, multiprocessing (SMP) dhe multi-core (CMP).
FPU Mandel

Ky pikë referimi vlerëson performancën me pikë lundruese me precizion të dyfishtë (precizion 64-bit) duke simuluar disa fragmente fraktal të Mandelbrot. Kodi për këtë test është shkruar në gjuhën e asamblesë dhe është optimizuar për bërthamat më të njohura të procesorëve AMD, Intel dhe VIA duke aplikuar shtesat e përshtatshme të grupit të instruksioneve x87, SSE2, AVX, AVX2, FMA dhe FMA4. Mandel FPU mbështet hiperthreading, multiprocessing (SMP) dhe multi-core (CMP).
FPU SinJulia

Testi vlerëson performancën e pikës lundruese me precizion të lartë (precizion 80-bit) përmes llogaritjeve kornizë për kornizë duke përdorur një fraktal të modifikuar Julia. Kodi për këtë test është i shkruar në gjuhën e asamblesë, është i optimizuar për bërthamat më të njohura të procesorit nga AMD, Intel dhe VIA, dhe lejon përdorimin e udhëzimeve trigonometrike dhe eksponenciale në arkitekturën x87. SinJulia FPU mbështet hiperthreading, multiprocessing (SMP) dhe multi-core (CMP).
 Përshëndetje të gjithëve Sot detyra ime është t'ju shkruaj kuptimin e një fjale të tillë si FPU, mirë, ose më saktë, nuk është as një fjalë, por një shkurtim. Dhe qëndron për Floating Point Unit dhe a e dini se çfarë është? Ky është një bllok që kryen operacione me pikë lundruese, si presje. Mund të thuash gjithashtu se ky është një bashkëprocesor matematik.
Përshëndetje të gjithëve Sot detyra ime është t'ju shkruaj kuptimin e një fjale të tillë si FPU, mirë, ose më saktë, nuk është as një fjalë, por një shkurtim. Dhe qëndron për Floating Point Unit dhe a e dini se çfarë është? Ky është një bllok që kryen operacione me pikë lundruese, si presje. Mund të thuash gjithashtu se ky është një bashkëprocesor matematik.
FPU ndihmon njësinë përpunuese (CPU) të kryejë operacione matematikore. Më parë, mirë, shumë, shumë kohë më parë, FPU ishte e ndarë, dhe vetëm atëherë në 1989 u bë pjesë e procesorit. Edhe pse e gjithë kjo është ende antikitet.
Kam gjetur një foto në temën që tregohet këtu, por sigurisht që nuk e kuptoj vërtet:

Sidoqoftë, jam i befasuar që nuk kam dëgjuar më parë për FPU, duke pasur parasysh faktin se fjalë të tilla si Northwood dhe Prescott (ato janë shkruar në foton më lart), këto fjalë janë të njohura për mua: këto janë bërthamat e procesorëve Pentium 4. Unë kam qenë vetëm në të kaluarën një fans i madh i Pentium 4..
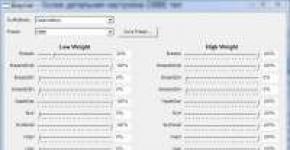
Në rregull, ja çfarë mësova tjetër që ishte interesante. A e dini se ekziston një program i quajtur AIDA64? Epo, ky është një program për të zbuluar temperaturën e procesorit, kartës video dhe në përgjithësi gjithçka që është e mundur. Epo, ky program ka edhe një test stresi, mund të testoni kompjuterin tuaj për qëndrueshmëri, si të thuash. Epo, nëse e ekzekutoni këtë test, domethënë hapni dritaren e testimit, atëherë do të ketë një listë të asaj që do të testohet, dhe midis këtyre kutive të kontrollit ka edhe diçka si Stress FPU:

Epo, siç e kuptoj unë, FPU është një bashkëprocesor matematikor, apo jo? Ndonëse nuk e di a është marrëzi apo jo, por në një faqe tjetër shkruhet se FPU në AIDA64 është një test i ventilatorëve ftohës që janë në kompjuter... Por ky duket se është informacion i pasaktë, mendoj se FPU është ende një bashkëprocesor
Këtu gjeta tabelën, shikoni:

Sinqerisht, nuk e di se ku saktësisht, por duket se ka një bashkëprocesor Intel 287-10 FPU, domethënë, duket se vjen veçmas. Por ku ndodhet saktësisht, nuk mund të them me siguri, mjerisht. Në çdo rast, e gjithë kjo është një lashtësi e fortë. Tani FPU është tashmë në proces dhe në përgjithësi pak njerëz dinë për të, sepse nuk është veçanërisht interesante, megjithatë, ja çfarë mendova: a ndikon disi në performancën?