Sieht aus wie Robots TXT. Empfehlungen zum Einrichten der Robots-TXT-Datei
Jeder Blog hat darauf seine eigene Antwort. Daher geraten Neulinge in der Suchmaschinenwerbung oft in Verwirrung, etwa so:
Was für Roboter sind das?
Datei robots.txt oder Indexdatei- ein normales Textdokument in UTF-8-Kodierung, gültig für die Protokolle http, https und FTP. Die Datei gibt Suchrobotern Empfehlungen: Welche Seiten/Dateien sollten gecrawlt werden. Wenn die Datei Zeichen in einer anderen Kodierung als UTF-8 enthält, werden diese möglicherweise von Suchrobotern falsch verarbeitet. Die in der robots.txt-Datei aufgeführten Regeln gelten nur für den Host, das Protokoll und die Portnummer, auf dem sich die Datei befindet.
Die Datei sollte sich im Stammverzeichnis als Nur-Text-Dokument befinden und verfügbar sein unter: https://site.com.ua/robots.txt.
In anderen Dateien ist es üblich, BOM (Byte Order Mark) zu kennzeichnen. Dies ist ein Unicode-Zeichen, das zur Bestimmung der Bytereihenfolge beim Lesen von Informationen verwendet wird. Sein Codezeichen ist U+FEFF. Am Anfang der robots.txt-Datei wird die Bytesequenzmarkierung ignoriert.
Google hat eine Größenbeschränkung für die robots.txt-Datei festgelegt – sie sollte nicht mehr als 500 KB wiegen.
Okay, wenn Sie sich für rein technische Details interessieren, ist die robots.txt-Datei eine Beschreibung in Backus-Naur-Form (BNF). Hierbei werden die Regeln von RFC 822 verwendet.
Bei der Verarbeitung von Regeln in der robots.txt-Datei erhalten Suchroboter eine von drei Anweisungen:
- Teilzugriff: Das Scannen einzelner Website-Elemente ist möglich.
- Vollzugriff: Sie können alles scannen;
- Vollständiges Verbot: Der Roboter kann nichts scannen.
Beim Scannen der robots.txt-Datei erhalten Robots die folgenden Antworten:
- 2xx - der Scan war erfolgreich;
- 3xx - Der Suchroboter folgt der Weiterleitung, bis er eine weitere Antwort erhält. In den meisten Fällen unternimmt der Roboter fünf Versuche, eine andere Antwort als eine 3xx-Antwort zu erhalten. Anschließend wird ein 404-Fehler protokolliert.
- 4xx — Der Suchroboter glaubt, dass es möglich ist, den gesamten Inhalt der Website zu crawlen.
- 5xx — Da sie als vorübergehende Serverfehler gewertet werden, ist das Scannen vollständig untersagt. Der Roboter greift auf die Datei zu, bis er eine weitere Antwort erhält. Der Google-Suchroboter kann feststellen, ob die Antwort auf fehlende Seiten auf der Website richtig oder falsch konfiguriert ist, d. h. ob die Seite anstelle eines 404-Fehlers eine 5xx-Antwort zurückgibt In diesem Fall wird die Seite mit dem Antwortcode 404 verarbeitet.
Es ist noch nicht bekannt, wie die robots.txt-Datei verarbeitet wird, auf die aufgrund von Serverproblemen mit dem Internetzugang nicht zugegriffen werden kann.
Warum benötigen Sie eine robots.txt-Datei?
Beispielsweise sollten Roboter manchmal Folgendes nicht besuchen:
- Seiten mit persönlichen Informationen der Benutzer auf der Website;
- Seiten mit verschiedenen Formularen zum Versenden von Informationen;
- Spiegelseiten;
- Suchergebnisseiten.
Wichtig: Auch wenn sich die Seite in der robots.txt-Datei befindet, besteht die Möglichkeit, dass sie in den Ergebnissen erscheint, wenn auf der Website oder irgendwo auf einer externen Ressource ein Link dazu gefunden wurde.
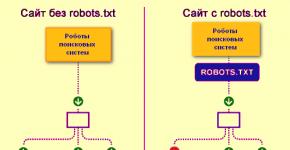
So sehen Suchmaschinen-Robots eine Website mit und ohne robots.txt-Datei:

Ohne robots.txt können Informationen, die vor neugierigen Blicken verborgen bleiben sollten, in den Suchergebnissen landen, was sowohl Ihnen als auch der Website schadet.
So sieht der Suchmaschinenroboter die robots.txt-Datei:

Google hat die robots.txt-Datei auf der Website erkannt und die Regeln ermittelt, nach denen die Seiten der Website gecrawlt werden sollen
So erstellen Sie eine robots.txt-Datei
Verwenden Sie Notepad, Notepad, Sublime oder einen anderen Texteditor.
User-Agent - Visitenkarte für Roboter
Benutzeragent – eine Regel darüber, welche Roboter die in der robots.txt-Datei beschriebenen Anweisungen anzeigen müssen. Derzeit sind 302 Suchroboter bekannt
Darin heißt es, dass wir in robots.txt Regeln für alle Suchroboter festlegen.
Für Google ist der Hauptroboter der Googlebot. Wenn wir nur dies berücksichtigen wollen, sieht der Eintrag in der Datei so aus:
In diesem Fall crawlen alle anderen Robots den Inhalt basierend auf ihren Anweisungen zur Verarbeitung einer leeren robots.txt-Datei.
Für Yandex ist der Hauptroboter... Yandex:
Weitere Spezialroboter:
- Googlebot-Neuigkeiten— um nach Neuigkeiten zu suchen;
- Medienpartner-Google– für den AdSense-Dienst;
- AdsBot-Google— um die Qualität der Zielseite zu überprüfen;
- YandexImages— Yandex.Images-Indexer;
- Googlebot-Bild- für Bilder;
- YandexMetrika— Yandex.Metrica-Roboter;
- YandexMedia— ein Roboter, der Multimediadaten indiziert;
- YaDirectFetcher— Yandex.Direct-Roboter;
- Googlebot-Video— für Video;
- Googlebot-Mobile- für die mobile Version;
- YandexDirectDyn— dynamischer Banner-Generierungsroboter;
- YandexBlogs– ein Blog-Suchroboter, der Beiträge und Kommentare indiziert;
- YandexMarket— Yandex.Market-Roboter;
- YandexNews— Yandex.News-Roboter;
- YandexDirect— lädt Informationen über den Inhalt von Partnerseiten des Werbenetzwerks herunter, um deren Themen für die Auswahl relevanter Werbung zu klären;
- YandexPagechecker— Mikro-Markup-Validator;
- YandexCalendar— Yandex.Calendar-Roboter.
Nicht zulassen – „Steine“ platzieren
Der Einsatz lohnt sich, wenn sich die Website im Verbesserungsprozess befindet und Sie nicht möchten, dass sie in ihrem aktuellen Zustand in den Suchergebnissen erscheint.
Es ist wichtig, diese Regel zu entfernen, sobald die Website für Benutzer sichtbar ist. Leider vergessen viele Webmaster dies.
Beispiel. So richten Sie eine Disallow-Regel ein, um Robots anzuweisen, den Inhalt eines Ordners nicht anzuzeigen /papka/:


Diese Zeile verbietet die Indizierung aller Dateien mit der Erweiterung .gif
Erlauben – wir dirigieren die Roboter
Zulassen ermöglicht das Scannen jeder Datei/Anweisung/Seite. Nehmen wir an, Sie möchten, dass Roboter nur Seiten anzeigen können, die mit /catalog beginnen, und alle anderen Inhalte schließen können. In diesem Fall ist folgende Kombination vorgeschrieben:

Zulassen- und Nichtzulassen-Regeln werden nach URL-Präfixlänge (vom kleinsten zum größten) sortiert und nacheinander angewendet. Wenn mehr als eine Regel mit einer Seite übereinstimmt, wählt der Roboter die letzte Regel in der sortierten Liste aus.
Host – Wählen Sie eine Spiegel-Site aus
Host ist eine der obligatorischen Regeln für robots.txt; sie teilt dem Yandex-Roboter mit, welche Spiegel der Website für die Indizierung berücksichtigt werden sollen.
Ein Site-Mirror ist eine exakte oder nahezu exakte Kopie einer Site, die unter verschiedenen Adressen verfügbar ist.
Der Roboter wird bei der Suche nach Site-Spiegeln nicht verwirrt und versteht, dass der Hauptspiegel in der robots.txt-Datei angegeben ist. Die Site-Adresse wird ohne das Präfix „http://“ angegeben. Wenn die Site jedoch auf HTTPS läuft, muss das Präfix „https://“ angegeben werden.
So schreiben Sie diese Regel:

Ein Beispiel für eine robots.txt-Datei, wenn die Site mit dem HTTPS-Protokoll läuft:

Sitemap – medizinische Sitemap
Sitemap teilt Robotern mit, dass sich alle für die Indexierung erforderlichen Website-URLs unter befinden http://site.ua/sitemap.xml. Bei jedem Crawl prüft der Roboter, welche Änderungen an dieser Datei vorgenommen wurden, und aktualisiert schnell die Informationen über die Website in den Suchmaschinendatenbanken.

Crawl-Delay – Stoppuhr für schwache Server
Crawl-Verzögerung ist ein Parameter, mit dem der Zeitraum festgelegt werden kann, nach dem Seiten der Website geladen werden. Diese Regel ist relevant, wenn Sie einen schwachen Server haben. In diesem Fall kann es zu langen Verzögerungen kommen, wenn Suchroboter auf die Seiten der Website zugreifen. Dieser Parameter wird in Sekunden gemessen.

Clean-param – Duplicate-Content-Jäger
Clean-param hilft beim Umgang mit Get-Parametern, um die Duplizierung von Inhalten zu vermeiden, die möglicherweise an verschiedenen dynamischen Adressen (mit Fragezeichen) verfügbar sind. Solche Adressen werden angezeigt, wenn die Site über verschiedene Sortierungen, Sitzungs-IDs usw. verfügt.
Nehmen wir an, die Seite ist unter den folgenden Adressen verfügbar:
www.site.com/catalog/get_phone.ua?ref=page_1&phone_id=1
www.site.com/catalog/get_phone.ua?ref=page_2&phone_id=1
www.site.com/catalog/get_phone.ua?ref=page_3&phone_id=1
In diesem Fall sieht die robots.txt-Datei so aus:

Hier ref gibt an, woher der Link kommt, also steht er ganz am Anfang und erst dann wird der Rest der Adresse angegeben.
Bevor Sie jedoch mit der Referenzdatei fortfahren, müssen Sie sich noch über einige Zeichen informieren, die beim Schreiben einer robots.txt-Datei verwendet werden.
Symbole in robots.txt
Die Hauptzeichen der Datei sind „/, *, $, #“.
Mit Hilfe Schrägstrich „/“ Wir zeigen, dass wir die Erkennung durch Roboter verhindern wollen. Wenn die Disallow-Regel beispielsweise einen Schrägstrich enthält, verbieten wir das Scannen der gesamten Website. Mit zwei Schrägstrichen können Sie das Scannen eines bestimmten Verzeichnisses verhindern, zum Beispiel: /catalog/.
Dieser Eintrag besagt, dass wir das Scannen des gesamten Inhalts des Katalogordners verbieten, aber wenn wir /catalog schreiben, werden wir alle Links auf der Site verbieten, die mit /catalog beginnen.
Sternchen „*“ bezeichnet eine beliebige Zeichenfolge in der Datei. Es wird nach jeder Regel platziert.
Dieser Eintrag besagt, dass alle Robots keine Dateien mit der Erweiterung .gif im Ordner /catalog/ indizieren sollten
Dollarzeichen «$» schränkt die Aktionen des Sternchenzeichens ein. Wenn Sie den gesamten Inhalt des Katalogordners blockieren möchten, aber keine URLs blockieren können, die /catalog enthalten, sieht der Eintrag in der Indexdatei wie folgt aus:
Netz "#" Wird für Kommentare verwendet, die ein Webmaster für sich selbst oder andere Webmaster hinterlässt. Der Roboter wird sie beim Scannen der Website nicht berücksichtigen.
Zum Beispiel:
Wie eine ideale robots.txt aussieht

Die Datei öffnet den Inhalt der Site zur Indizierung, der Host wird registriert und eine Sitemap angezeigt, die es Suchmaschinen ermöglicht, immer die Adressen zu sehen, die indiziert werden sollen. Die Regeln für Yandex werden separat angegeben, da nicht alle Roboter die Host-Anweisungen verstehen.
Aber beeilen Sie sich nicht, den Inhalt der Datei auf sich selbst zu kopieren – jede Site muss über einzigartige Regeln verfügen, die von der Art der Site und dem CMS abhängen. Daher lohnt es sich, beim Ausfüllen der robots.txt-Datei alle Regeln zu beachten.
So überprüfen Sie Ihre robots.txt-Datei
Wenn Sie wissen möchten, ob die robots.txt-Datei korrekt ausgefüllt wurde, überprüfen Sie sie in den Webmaster-Tools Google und Yandex. Geben Sie einfach über den Link den Quellcode der robots.txt-Datei in das Formular ein und geben Sie die zu prüfende Seite an.
So füllen Sie die robots.txt-Datei nicht aus
Beim Ausfüllen einer Indexdatei passieren oft ärgerliche Fehler, die mit gewöhnlicher Unaufmerksamkeit oder Eile verbunden sind. Nachfolgend finden Sie eine Tabelle mit Fehlern, auf die ich in der Praxis gestoßen bin.


2. Mehrere Ordner/Verzeichnisse in einer Disallow-Anweisung schreiben:

Ein solcher Eintrag kann Suchroboter verwirren; sie verstehen möglicherweise nicht, was genau sie nicht indizieren sollen: entweder den ersten oder den letzten Ordner, daher müssen Sie jede Regel separat schreiben.

3. Die Datei selbst muss aufgerufen werden nur robots.txt, und nicht Robots.txt, ROBOTS.TXT oder irgendetwas anderes.
4. Sie können die User-Agent-Regel nicht leer lassen – Sie müssen angeben, welcher Roboter die in der Datei geschriebenen Regeln berücksichtigen soll.
5. Zusätzliche Zeichen in der Datei (Schrägstriche, Sternchen).
6. Hinzufügen von Seiten zur Datei, die nicht im Index enthalten sein sollen.
Nicht standardmäßige Verwendung von robots.txt
Zusätzlich zu den direkten Funktionen kann die Karteikarte zu einer Plattform für Kreativität und zur Suche nach neuen Mitarbeitern werden.
Hier ist eine Site, auf der robots.txt selbst eine kleine Site mit Arbeitselementen und sogar einem Anzeigenblock ist.




Die Datei wird vor allem von SEO-Agenturen als Plattform für die Suche nach Spezialisten genutzt. Wer sonst könnte von seiner Existenz wissen? :) :)

Und Google hat eine spezielle Datei menschen.txt, damit Sie nicht an eine Diskriminierung von Leder- und Fleischspezialisten denken.

Schlussfolgerungen
Mit Robots.txt können Sie Suchrobotern Anweisungen geben, für sich und Ihre Marke werben und nach Spezialisten suchen. Dies ist ein großartiges Feld zum Experimentieren. Das Wichtigste ist, sich an das korrekte Ausfüllen der Datei und typische Fehler zu erinnern.
Regeln, auch Direktiven genannt, in der robots.txt-Datei:
- Benutzeragent – eine Regel darüber, welche Roboter die in robots.txt beschriebenen Anweisungen anzeigen müssen.
- Disallow gibt Empfehlungen dazu, welche Informationen nicht gescannt werden sollten.
- Sitemap teilt Robotern mit, dass sich alle für die Indexierung erforderlichen Site-URLs unter http://site.ua/sitemap.xml befinden.
- Der Host teilt dem Yandex-Roboter mit, welche der Site-Spiegel für die Indizierung berücksichtigt werden sollen.
- Zulassen ermöglicht das Scannen jeder Datei/Anweisung/Seite.
Zeichen beim Kompilieren von robots.txt:
- Das Dollarzeichen „$“ begrenzt die Aktionen des Sternchenzeichens.
- Mit dem Schrägstrich „/“ geben wir an, dass wir es vor der Erkennung durch Roboter verbergen möchten.
- Das Sternchen „*“ steht für eine beliebige Zeichenfolge in der Datei. Es wird nach jeder Regel platziert.
- Der Hash „#“ wird verwendet, um Kommentare anzuzeigen, die ein Webmaster für sich selbst oder andere Webmaster schreibt.
Setzen Sie die Indexdatei mit Bedacht ein – und die Site wird immer in den Suchergebnissen angezeigt.
Hierfür sind Arbeitsanweisungen erforderlich; Suchmaschinen stellen hier keine Ausnahme dar und haben daher eine spezielle Datei mit dem Namen „ robots.txt. Diese Datei sollte sich im Stammordner Ihrer Site befinden, oder sie kann virtuell sein, muss aber auf Anfrage geöffnet werden: www.yoursite.ru/robots.txt
Suchmaschinen haben längst gelernt, die notwendigen HTML-Dateien von den internen Skriptsätzen Ihres CMS-Systems zu unterscheiden, oder besser gesagt, sie haben gelernt, Links zu Inhaltsartikeln und allerlei Müll zu erkennen. Daher vergessen viele Webmaster bereits, Roboter für ihre Websites zu verwenden, und denken, dass alles gut werden wird. Ja, sie haben zu 99 % Recht, denn wenn Ihre Website nicht über diese Datei verfügt, sind Suchmaschinen bei der Suche nach Inhalten grenzenlos, aber es gibt Nuancen, deren Fehler im Voraus behoben werden können.
Wenn Sie Probleme mit dieser Datei auf der Website haben, schreiben Sie Kommentare zu diesem Artikel und ich werde Ihnen dabei schnell und absolut kostenlos helfen. Sehr häufig machen Webmaster darin geringfügige Fehler, die zu einer schlechten Indexierung der Website oder sogar zum Ausschluss aus dem Index führen.
Wozu dient robots.txt?
Die Datei robots.txt wird erstellt, um die korrekte Indexierung der Website durch Suchmaschinen zu konfigurieren. Das heißt, es enthält Regeln für Erlaubnisse und Verbote für bestimmte Pfade Ihrer Website oder Art von Inhalten. Aber das ist kein Allheilmittel. Alle Regeln in einer Robots-Datei sind keine Richtlinien Befolgen Sie diese genau, sondern stellen lediglich eine Empfehlung für Suchmaschinen dar. Google schreibt beispielsweise:
Sie können die robots.txt-Datei nicht verwenden, um eine Seite aus den Google-Suchergebnissen auszublenden. Andere Seiten können darauf verlinken und es wird trotzdem indiziert.
Suchroboter entscheiden selbst, was indexiert wird und was nicht und wie sie sich auf der Website verhalten. Jede Suchmaschine hat ihre eigenen Aufgaben und Funktionen. Egal wie sehr wir wollen, das ist keine Möglichkeit, sie zu zähmen.
Es gibt jedoch einen Trick, der nicht direkt mit dem Thema dieses Artikels zusammenhängt. Um vollständig zu verhindern, dass Robots eine Seite indizieren und in den Suchergebnissen anzeigen, müssen Sie Folgendes schreiben:
Kommen wir zurück zu den Robotern. Die Regeln in dieser Datei können den Zugriff auf die folgenden Dateitypen blockieren oder zulassen:
- Nicht-grafische Dateien. Im Grunde handelt es sich hierbei um HTML-Dateien, die einige Informationen enthalten. Sie können doppelte Seiten oder Seiten schließen, die keine nützlichen Informationen liefern (Paginierungsseiten, Kalenderseiten, Archivseiten, Profilseiten usw.).
- Grafikdateien. Wenn Sie möchten, dass Seitenbilder bei Suchanfragen nicht angezeigt werden, können Sie dies in den Robots einstellen.
- Ressourcendateien. Mithilfe von Robotern können Sie außerdem die Indizierung verschiedener Skripte, CSS-Stildateien und anderer unwichtiger Ressourcen blockieren. Sie sollten jedoch keine Ressourcen blockieren, die für den visuellen Teil der Website für Besucher verantwortlich sind (wenn Sie beispielsweise die CSS- und JS-Dateien der Website schließen, die schöne Blöcke oder Tabellen anzeigen, wird der Suchroboter dies nicht sehen und sich darüber beschweren Es).
Um deutlich zu zeigen, wie Roboter funktionieren, sehen Sie sich das Bild unten an:
Ein Suchroboter, der einer Website folgt, prüft die Indexierungsregeln und beginnt dann mit der Indexierung gemäß den Empfehlungen der Datei.  Abhängig von den Regeleinstellungen weiß die Suchmaschine, was indiziert werden kann und was nicht.
Abhängig von den Regeleinstellungen weiß die Suchmaschine, was indiziert werden kann und was nicht.
Aus der robots.txt-Datei intax
Um Regeln für Suchmaschinen zu schreiben, werden in der Robots-Datei Anweisungen mit verschiedenen Parametern verwendet, mit deren Hilfe die Robots folgen. Beginnen wir mit der allerersten und wahrscheinlich wichtigsten Richtlinie:
User-Agent-Anweisung
User-Agent— Mit dieser Direktive geben Sie den Namen des Roboters an, der die Empfehlungen in der Datei verwenden soll. Offiziell gibt es 302 dieser Roboter in der Internetwelt. Natürlich können Sie Regeln für jeden einzeln schreiben, aber wenn Sie keine Zeit dafür haben, schreiben Sie einfach:
User-Agent: *
*-bedeutet in diesem Beispiel „Alle“. Diese. Ihre robots.txt-Datei sollte mit „Wer genau“ beginnen, für den die Datei bestimmt ist. Um sich nicht mit allen Namen der Roboter herumzuschlagen, schreiben Sie einfach ein „Sternchen“ in die User-Agent-Anweisung.
Ich gebe Ihnen detaillierte Listen der Roboter beliebter Suchmaschinen:
Google - Googlebot- Hauptroboter
Andere Google-RoboterGooglebot-Neuigkeiten– Nachrichtensuchroboter
Googlebot-Bild— Roboterbilder
Googlebot-Video- Robotervideo
Googlebot-Mobile— Roboter-Mobilversion
AdsBot-Google— Roboter zur Qualitätsprüfung der Zielseite
Medienpartner-Google– AdSense-Serviceroboter
Yandex - YandexBot- Hauptindexierungsroboter;
Andere Yandex-RoboterDisallow- und Allow-Anweisungen
Nicht zulassen- die grundlegendste Regel bei Robots. Mit Hilfe dieser Richtlinie verbieten Sie die Indexierung bestimmter Stellen auf Ihrer Website. Die Direktive ist wie folgt geschrieben:
Nicht zulassen:
Sehr oft sieht man die Disallow-Direktive: leer, d.h. Sagen Sie dem Roboter angeblich, dass auf der Website nichts verboten ist, und indizieren Sie, was Sie wollen. Seien Sie aufmerksam! Wenn Sie / in disallow eingeben, wird die Site vollständig von der Indizierung ausgeschlossen.
Daher sieht die Standardversion von robots.txt, die „die Indizierung der gesamten Website für alle Suchmaschinen ermöglicht“, so aus:
User-Agent: * Nicht zulassen:
Wenn Sie nicht wissen, was Sie in robots.txt schreiben sollen, aber irgendwo davon gehört haben, kopieren Sie einfach den obigen Code, speichern Sie ihn in einer Datei namens robots.txt und laden Sie ihn in das Stammverzeichnis Ihrer Website hoch. Oder erstellen Sie gar nichts, denn auch ohne es indizieren Roboter alles auf Ihrer Website. Oder lesen Sie den Artikel bis zum Ende und Sie werden verstehen, was Sie auf der Website schließen müssen und was nicht.
Gemäß den Roboterregeln muss die Disallow-Anweisung erforderlich sein.
Diese Anweisung kann sowohl einen Ordner als auch eine einzelne Datei verbieten.
Wenn Sie wollen Ban-Ordner du solltest schreiben:
Nicht zulassen: /Ordner/
Wenn Sie wollen eine bestimmte Datei verbieten:
Nicht zulassen: /images/img.jpg
Wenn Sie wollen bestimmte Dateitypen verbieten:
Nicht zulassen: /*.png$
Reguläre Ausdrücke werden von vielen Suchmaschinen nicht unterstützt. Google unterstützt.
Erlauben– Direktive „allowing“ in Robots.txt. Dadurch kann der Roboter einen bestimmten Pfad oder eine bestimmte Datei in einem verbotenen Verzeichnis indizieren. Bis vor kurzem wurde es nur von Yandex verwendet. Google hat dies erkannt und begonnen, es ebenfalls zu verwenden. Zum Beispiel:
Zulassen: /content Nicht zulassen: /
Diese Anweisungen verhindern, dass der gesamte Inhalt der Website mit Ausnahme des Inhaltsordners indiziert wird. Oder hier sind einige andere in letzter Zeit beliebte Richtlinien:
Zulassen: /template/*.js Zulassen: /template/*.css Nicht zulassen: /template
diese Werte Erlauben Sie die Indizierung aller CSS- und JS-Dateien auf der Website, aber sie lassen nicht zu, dass alles im Ordner mit Ihrer Vorlage indiziert wird. Im vergangenen Jahr hat Google viele Briefe an Webmaster mit folgendem Inhalt verschickt:
Der Googlebot kann nicht auf CSS- und JS-Dateien auf der Website zugreifen
Und der dazugehörige Kommentar: Wir haben ein Problem mit Ihrer Website festgestellt, das möglicherweise das Crawlen verhindert. Googlebot kann aufgrund von Einschränkungen in der robots.txt-Datei keinen JavaScript-Code und/oder CSS-Dateien verarbeiten. Diese Daten werden benötigt, um die Leistung der Website zu bewerten. Wenn der Zugriff auf Ressourcen blockiert wird, kann sich daher die Position Ihrer Website in der Suche verschlechtern..
Wenn Sie die beiden Zulassungsanweisungen, die im letzten Code geschrieben sind, zu Ihrer Robots.txt hinzufügen, werden Ihnen keine ähnlichen Nachrichten von Google angezeigt.
Und die Verwendung von Sonderzeichen in robots.txt
Nun zu den Zeichen in den Richtlinien. Grundlegende Zeichen (Sonderzeichen), um dies zu verbieten oder zu erlauben /,*,$
Über den Schrägstrich „/“
Der Schrägstrich in robots.txt ist sehr irreführend. Ich habe mehrere Dutzend Mal eine interessante Situation beobachtet, als aus Unwissenheit Folgendes zur robots.txt hinzugefügt wurde:
User-Agent: * Nicht zulassen: /
Weil sie irgendwo über die Struktur der Site gelesen und diese auf ihre Site kopiert haben. Aber in diesem Fall Sie die Indizierung der gesamten Website verbieten. Um die Indizierung eines bestimmten Verzeichnisses mit allen Interna zu verhindern, müssen Sie unbedingt / am Ende einfügen. Wenn Sie beispielsweise Disallow: /seo schreiben, werden absolut alle Links auf Ihrer Website, die das Wort seo enthalten, nicht indiziert. Auch wenn es ein Ordner /seo/ sein wird, obwohl es eine Kategorie /seo-tool/ sein wird, obwohl es ein Artikel /seo-best-of-the-best-soft.html sein wird, wird das alles nicht der Fall sein indiziert werden.
Schauen Sie sich alles genau an / in Ihrer robots.txt
Setzen Sie / immer am Ende von Verzeichnissen. Wenn Sie „/“ in „Disallow“ setzen, verhindern Sie, dass die gesamte Site indiziert wird. Wenn Sie „/“ in „Allow“ nicht setzen, verhindern Sie auch, dass die gesamte Site indiziert wird. / – bedeutet in gewissem Sinne „Alles, was der Richtlinie / folgt“.
Über Sternchen * in robots.txt
Das Sonderzeichen * bezeichnet eine beliebige (auch leere) Zeichenfolge. Sie können es überall in Robotern wie diesem verwenden:
Benutzeragent: * Nicht zulassen: /papka/*.aspx Nicht zulassen: /*old
Verbietet alle Dateien mit der Erweiterung aspx im Verzeichnis papka und verbietet außerdem nicht nur den Ordner /old, sondern auch die Direktive /papka/old. Schwierig? Daher empfehle ich Ihnen nicht, mit dem *-Symbol in Ihren Robotern herumzuspielen.
Standard in Datei mit Indizierungs- und Sperrregeln robots.txt ist in allen Anweisungen *!
Über das Sonderzeichen $
Das Sonderzeichen $ in Robots beendet die Wirkung des Sonderzeichens *. Zum Beispiel:
Nicht zulassen: /menu$
Diese Regel verbietet „/menu“, nicht jedoch „/menu.html“, d. h. Die Datei verbietet Suchmaschinen nur die Direktive /menu und kann nicht alle Dateien verbieten, deren URL das Wort „menu“ enthält.
Die Host-Direktive
Die Host-Regel funktioniert also nur in Yandex es ist optional, bestimmt es die Hauptdomäne aus Ihren Site-Mirror-Dateien, falls vorhanden. Sie haben beispielsweise eine Domain dom.com, es wurden aber auch folgende Domains gekauft und konfiguriert: dom2.com, dom3,com, dom4.com und von diesen erfolgt eine Weiterleitung zur Hauptdomain dom.com
Damit Yandex schnell feststellen kann, welche davon die Hauptseite (Host) ist, schreiben Sie das Hostverzeichnis in Ihre robots.txt:
Host: Website
Wenn Ihre Site keine Mirrors hat, müssen Sie diese Regel nicht festlegen. Überprüfen Sie jedoch zunächst Ihre Website anhand der IP-Adresse. Möglicherweise wird Ihre Hauptseite von dort aus geöffnet, und Sie sollten den Hauptspiegel registrieren. Oder vielleicht hat jemand alle Informationen von Ihrer Website kopiert und eine exakte Kopie erstellt. Ein Eintrag in robots.txt, falls diese ebenfalls gestohlen wurden, hilft Ihnen dabei.
Es sollte einen Host-Eintrag und ggf. einen registrierten Port geben. (Host: Site:8080)
Crawl-Delay-Anweisung
Diese Anweisung wurde erstellt, um die Möglichkeit einer Überlastung Ihres Servers zu verhindern. Suchmaschinen-Bots können Hunderte von Anfragen gleichzeitig an Ihre Website senden. Wenn Ihr Server schwach ist, kann dies zu geringfügigen Störungen führen. Um dies zu verhindern, haben wir eine Regel für Crawling-Delay-Robots entwickelt – dies ist der Mindestzeitraum zwischen dem Laden einer Seite auf Ihrer Website. Es wird empfohlen, den Standardwert für diese Anweisung auf 2 Sekunden festzulegen. In Robots sieht es so aus:
Crawl-Verzögerung: 2
Diese Anweisung funktioniert für Yandex. In Google können Sie die Crawling-Frequenz im Webmaster-Panel im Abschnitt „Site-Einstellungen“ oben rechts mit dem „Zahnrad“ festlegen.
Clean-param-Direktive
Dieser Parameter gilt ebenfalls nur für Yandex. Wenn Site-Seitenadressen dynamische Parameter enthalten, die sich nicht auf deren Inhalt auswirken (z. B. Sitzungskennungen, Benutzer, Referrer usw.), können Sie diese mithilfe der Clean-param-Direktive beschreiben.
Mithilfe dieser Informationen lädt der Yandex-Roboter doppelte Informationen nicht wiederholt nach. Dadurch wird die Effizienz beim Crawlen Ihrer Website erhöht und die Belastung des Servers verringert.
Die Website verfügt beispielsweise über folgende Seiten:
www.site.com/some_dir/get_book.pl?ref=site_1&book_id=123
Parameter ref wird nur verwendet, um zu verfolgen, von welcher Ressource die Anfrage stammt, und ändert den Inhalt nicht; an allen drei Adressen wird dieselbe Seite mit dem Buch book_id=123 angezeigt. Wenn Sie die Direktive dann wie folgt angeben:
Benutzeragent: Yandex Disallow: Clean-param: ref /some_dir/get_book.pl
Der Yandex-Roboter reduziert alle Seitenadressen auf eine:
www.site.com/some_dir/get_book.pl?ref=site_1&book_id=123,
Wenn auf der Site eine Seite ohne Parameter verfügbar ist:
www.site.com/some_dir/get_book.pl?book_id=123
dann kommt es darauf an, wenn es vom Roboter indiziert wird. Andere Seiten Ihrer Website werden häufiger gecrawlt, da keine Aktualisierung der Seiten erforderlich ist:
www.site.com/some_dir/get_book.pl?ref=site_2&book_id=123
www.site.com/some_dir/get_book.pl?ref=site_3&book_id=123
#für Adressen wie: www.site1.com/forum/showthread.php?s=681498b9648949605&t=8243 www.site1.com/forum/showthread.php?s=1e71c4427317a117a&t=8243 #robots.txt enthält: User-Agent: Yandex Disallow: Clean-param: s /forum/showthread.php
Sitemap-Richtlinie
Mit dieser Direktive geben Sie einfach den Speicherort Ihrer sitemap.xml an. Der Roboter merkt sich dies, „sagt Danke“ und analysiert es ständig entlang eines vorgegebenen Pfades. Es sieht aus wie das:
Sitemap: http://site/sitemap.xml
Schauen wir uns nun die allgemeinen Fragen an, die sich bei der Erstellung von Robotern stellen. Es gibt viele solcher Themen im Internet, daher analysieren wir die relevantesten und häufigsten.
Korrigieren Sie robots.txt
In diesem Wort steckt viel „richtig“, denn für eine Website auf einem CMS ist es richtig, auf einem anderen CMS führt es jedoch zu Fehlern. „Richtig konfiguriert“ ist für jeden Standort individuell. In Robots.txt müssen Sie die Indizierung derjenigen Abschnitte und Dateien ausschließen, die von Benutzern nicht benötigt werden und keinen Wert für Suchmaschinen bieten. Die einfachste und korrekteste Version von robots.txt
Benutzeragent: * Nicht zulassen: Sitemap: http://site/sitemap.xml Benutzeragent: Yandex Nicht zulassen: Host: site.com
Diese Datei enthält die folgenden Regeln: Einstellungen für Verbotsregeln für alle Suchmaschinen (User-Agent: *), die Indizierung der gesamten Website ist vollständig erlaubt („Disallow:“ oder Sie können „Allow: /“ angeben), den Host von Der Hauptspiegel für Yandex ist angegeben (Host: site.ncom) und der Speicherort Ihrer Sitemap.xml (Sitemap: .
Robots.txt für WordPress
Auch hier gibt es viele Fragen, eine Seite könnte ein Online-Shop sein, eine andere ein Blog, eine dritte eine Landingpage, eine vierte eine Visitenkartenseite für ein Unternehmen, und das alles könnte auf dem CMS WordPress und den Regeln für Roboter basieren ganz anders sein. Hier ist meine robots.txt für diesen Blog:
Benutzeragent: * Erlauben: /wp-content/uploads/ Erlauben: /wp-content/*.js$ Erlauben: /wp-content/*.css$ Erlauben: /wp-includes/*.js$ Erlauben: / wp-includes/*.css$ Disallow: /wp-login.php Disallow: /wp-register.php Disallow: /xmlrpc.php Disallow: /template.html Disallow: /wp-admin Disallow: /wp-includes Disallow: /wp-content Disallow: /category Disallow: /archive Disallow: */trackback/ Disallow: */feed/ Disallow: /?feed= Disallow: /job Disallow: /?.net/sitemap.xml
Hier gibt es viele Einstellungen, schauen wir sie uns gemeinsam an.
In WordPress zulassen. Die ersten Zulassungsregeln gelten für den Inhalt, der von Benutzern (dies sind Bilder im Upload-Ordner) und Robotern (dies sind CSS und JS zum Anzeigen von Seiten) benötigt. Es sind CSS und JS, über die sich Google oft beschwert, deshalb haben wir sie offen gelassen. Es war möglich, die All-Files-Methode durch einfaches Einfügen von „/*.css$“ zu verwenden, aber die Verbotszeile genau dieser Ordner, in denen sich die Dateien befanden, erlaubte nicht, sie für die Indizierung zu verwenden, sodass ich den Pfad angeben musste vollständig in die Verbotsmappe übernommen.
„Zulassen“ verweist immer auf den Pfad des Inhalts, der in „Nicht zulassen“ verboten ist. Wenn Ihnen etwas nicht verboten ist, sollten Sie nicht „allow“ hineinschreiben, weil Sie angeblich denken, Sie gäben dadurch einen Anstoß für Suchmaschinen, wie „Komm schon, hier ist eine URL für Sie, indizieren Sie sie schneller.“ So wird es nicht funktionieren.
In WordPress nicht zulassen. Es gibt viele Dinge, die in einem WP CMS verboten werden müssen. Viele verschiedene Plugins, viele verschiedene Einstellungen und Themen, eine Menge Skripte und verschiedene Seiten, die keine nützlichen Informationen enthalten. Aber ich ging noch einen Schritt weiter und habe die Indexierung aller Inhalte meines Blogs völlig verboten, mit Ausnahme der Artikel selbst (Beiträge) und der Seiten (über den Autor, Dienstleistungen). Ich habe sogar die Kategorien im Blog geschlossen. Ich werde sie öffnen, wenn sie für Suchanfragen optimiert sind und wenn es für jede von ihnen eine Textbeschreibung gibt, aber jetzt handelt es sich lediglich um doppelte Beitragsvorschauen, die Suchmaschinen nicht benötigen.
Nun, Host und Sitemap sind Standardanweisungen. Ich musste nur den Host separat für Yandex erstellen, habe mich aber nicht darum gekümmert. Jetzt werden wir wahrscheinlich mit Robots.txt für WP fertig sein.
So erstellen Sie robots.txt
Es ist nicht so schwierig, wie es auf den ersten Blick scheint. Sie müssen lediglich einen normalen Notizblock (Notepad) nehmen und die Daten für Ihre Site entsprechend den Einstellungen aus diesem Artikel dorthin kopieren. Wenn Ihnen dies jedoch schwer fällt, gibt es im Internet Ressourcen, mit denen Sie Robots für Ihre Websites generieren können:
Niemand wird Ihnen mehr über Ihre Robots.txt erzählen als diese Kameraden. Schließlich erstellen Sie für sie Ihre „verbotene Datei“.
Lassen Sie uns nun über einige kleinere Fehler sprechen, die bei Robotern auftreten können.
- « Leere Zeile„ – Es ist nicht akzeptabel, in der User-Agent-Direktive eine Leerzeile einzufügen.
- Bei Konflikt zwischen zwei Richtlinien Bei Präfixen gleicher Länge hat die Direktive Vorrang Erlauben.
- Für jede wird eine robots.txt-Datei verarbeitet nur eine Host-Direktive. Wenn in der Datei mehrere Anweisungen angegeben sind, verwendet der Roboter die erste.
- Richtlinie Clean-Param ist querschnittlich und kann daher an einer beliebigen Stelle in der robots.txt-Datei angegeben werden. Werden mehrere Anweisungen angegeben, werden diese alle vom Roboter berücksichtigt.
- Sechs Yandex-Roboter befolgen nicht die Regeln von Robots.txt (YaDirectFetcher, YandexCalendar, YandexDirect, YandexDirectDyn, YandexMobileBot, YandexAccessibilityBot). Um zu verhindern, dass sie auf der Website indiziert werden, sollten Sie für jeden von ihnen separate User-Agent-Parameter festlegen.
- User-Agent-Anweisung, muss immer über der Verbotsanweisung stehen.
- Eine Zeile für ein Verzeichnis. Sie können nicht mehrere Verzeichnisse in eine Zeile schreiben.
- Dateiname es sollte nur so sein: robots.txt. Keine Robots.txt, ROBOTS.txt usw. Nur Kleinbuchstaben im Titel.
- In der Richtlinie Gastgeber Sie sollten den Pfad zur Domain ohne http und ohne Schrägstriche schreiben. Falsch: Host: http://www.site.ru/, Richtig: Host: www.site.ru
- Wenn die Site ein sicheres Protokoll verwendet https in der Richtlinie Gastgeber(für den Yandex-Roboter) ist es notwendig, das Protokoll genau anzugeben, also Host: https://www.site.ru
Dieser Artikel wird aktualisiert, sobald interessante Fragen und Nuancen verfügbar werden.
Ich war bei dir, fauler Staurus.
Die Datei sitemap.xml und die korrekte robots.txt-Datei für die Site sind zwei obligatorische Dokumente, die zur schnellen und vollständigen Indexierung aller erforderlichen Seiten einer Webressource durch Suchroboter beitragen. Die korrekte Indexierung von Websites in Yandex und Google ist der Schlüssel zur erfolgreichen Blog-Werbung in Suchmaschinen.
Ich habe bereits geschrieben, wie man eine Sitemap im XML-Format erstellt und warum sie benötigt wird. Lassen Sie uns nun darüber sprechen, wie Sie die richtige robots.txt-Datei für eine WordPress-Site erstellen und warum diese im Allgemeinen benötigt wird. Detaillierte Informationen zu dieser Datei erhalten Sie bei Yandex bzw. Google selbst. Ich komme zum Kern und gehe am Beispiel meiner Datei auf die grundlegenden robots.txt-Einstellungen für WordPress ein.
Warum benötigen Sie eine robots.txt-Datei für eine Website?
Der robots.txt-Standard erschien bereits im Januar 1994. Beim Scannen einer Webressource suchen Suchroboter zunächst nach der Textdatei robots.txt, die sich im Stammordner der Website oder des Blogs befindet. Mit seiner Hilfe können wir bestimmte Regeln für Robots verschiedener Suchmaschinen festlegen, nach denen sie die Website indizieren.
Durch die korrekte Einrichtung von robots.txt können Sie:
- Duplikate und verschiedene Junk-Seiten aus dem Index ausschließen;
- die Indizierung von Seiten, Dateien und Ordnern verbieten, die wir verbergen möchten;
- verweigern Sie einigen Suchrobotern generell die Indizierung (z. B. Yahoo, um Informationen über eingehende Links vor Wettbewerbern zu verbergen);
- Geben Sie den Hauptspiegel der Website an (mit www oder ohne www);
- Geben Sie den Pfad zur Sitemap sitemap.xml an.
So erstellen Sie die richtige robots.txt-Datei für eine Website
Hierfür gibt es spezielle Generatoren und Plugins, besser ist es jedoch, dies manuell zu erledigen.
Sie müssen lediglich mit einem beliebigen Texteditor (z. B. Notepad oder Notepad++) eine normale Textdatei namens robots.txt erstellen und diese auf Ihr Hosting im Stammordner Ihres Blogs hochladen. In dieser Datei müssen bestimmte Anweisungen geschrieben werden, d.h. Indexierungsregeln für Roboter von Yandex, Google usw.
Wenn Sie zu faul sind, sich damit zu befassen, werde ich unten ein Beispiel für die aus meiner Sicht richtige robots.txt für WordPress aus meinem Blog geben. Sie können es verwenden, indem Sie den Domänennamen an drei Stellen ersetzen.
Regeln und Anweisungen für die Erstellung von Robots.txt
Für eine erfolgreiche Suchmaschinenoptimierung eines Blogs müssen Sie einige Regeln für die Erstellung von robots.txt kennen:
- Das Fehlen oder die leere robots.txt-Datei bedeutet, dass Suchmaschinen den gesamten Inhalt der Webressource indizieren dürfen.
- robots.txt sollte unter site.ru/robots.txt geöffnet werden, dem Roboter den Antwortcode 200 OK geben und nicht größer als 32 KB sein. Eine Datei, die sich nicht öffnen lässt (z. B. aufgrund eines 404-Fehlers) oder größer ist, wird als in Ordnung betrachtet.
- Die Anzahl der Anweisungen in der Datei sollte 1024 nicht überschreiten. Die Länge einer Zeile sollte 1024 Zeichen nicht überschreiten.
- Eine gültige robots.txt-Datei kann mehrere Anweisungen enthalten, von denen jede mit einer User-Agent-Anweisung beginnen und mindestens eine Disallow-Anweisung enthalten muss. Normalerweise schreiben sie Anweisungen in robots.txt für Google und alle anderen Roboter und separat für Yandex.
Grundlegende robots.txt-Anweisungen:
Benutzeragent – gibt an, an welchen Suchroboter die Anweisung gerichtet ist.
Das Symbol „*“ bedeutet, dass dies für alle Roboter gilt, zum Beispiel:
User-Agent: *
Wenn wir in robots.txt eine Regel für Yandex erstellen müssen, schreiben wir:
Benutzeragent: Yandex
Wenn eine Direktive für einen bestimmten Roboter angegeben wird, wird die User-agent: *-Direktive von diesem nicht berücksichtigt.
„Disallow“ und „Allow“ – verbieten bzw. erlauben Robots, die angegebenen Seiten zu indizieren. Alle Adressen müssen im Stammverzeichnis der Site angegeben werden, d. h. beginnend mit dem dritten Schrägstrich. Zum Beispiel:
- Allen Robots die Indizierung der gesamten Website verbieten:
User-Agent: *
Nicht zulassen: / - Yandex ist es untersagt, alle Seiten zu indizieren, die mit /wp-admin beginnen:
Benutzeragent: Yandex
Nicht zulassen: /wp-admin - Die leere Disallow-Direktive ermöglicht die Indizierung von allem und ähnelt Allow. Ich erlaube Yandex beispielsweise, die gesamte Website zu indizieren:
Benutzeragent: Yandex
Nicht zulassen: - Und umgekehrt verbiete ich allen Suchrobotern, alle Seiten zu indizieren:
User-Agent: *
Erlauben: - Allow- und Disallow-Anweisungen aus demselben User-Agent-Block werden nach URL-Präfixlänge sortiert und nacheinander ausgeführt. Wenn mehrere Anweisungen für eine Seite der Site geeignet sind, wird die letzte in der Liste ausgeführt. Jetzt spielt die Reihenfolge, in der sie geschrieben werden, keine Rolle, wenn der Roboter Anweisungen verwendet. Wenn die Direktiven Präfixe gleicher Länge haben, wird Allow zuerst ausgeführt. Diese Regeln traten am 8. März 2012 in Kraft. Beispielsweise können nur Seiten indiziert werden, die mit /wp-includes beginnen:
Benutzeragent: Yandex
Nicht zulassen: /
Erlauben: /wp-includes
Sitemap – Gibt die XML-Sitemap-Adresse an. Eine Site kann mehrere Sitemap-Anweisungen haben, die verschachtelt sein können. Alle Sitemap-Dateiadressen müssen in robots.txt angegeben werden, um die Site-Indizierung zu beschleunigen:
Sitemap: http://site/sitemap.xml.gz
Sitemap: http://site/sitemap.xml
Host – teilt dem Spiegelroboter mit, welcher Website-Spiegel als Hauptspiegel betrachtet werden soll.
Ist die Seite unter mehreren Adressen erreichbar (zum Beispiel mit www und ohne www), dann entstehen komplette doppelte Seiten, die vom Filter abgefangen werden können. Auch in diesem Fall wird möglicherweise nicht die Hauptseite indiziert, sondern die Hauptseite wird im Gegenteil aus dem Suchmaschinenindex ausgeschlossen. Um dies zu verhindern, verwenden Sie die Host-Direktive, die in der robots.txt-Datei nur für Yandex vorgesehen ist und es nur eine geben kann. Es wird nach Disallow und Allow geschrieben und sieht so aus:
Host: Website
Crawl-Verzögerung – legt die Verzögerung zwischen dem Herunterladen von Seiten in Sekunden fest. Wird verwendet, wenn eine hohe Auslastung vorliegt und der Server keine Zeit hat, Anfragen zu verarbeiten. Auf jungen Websites ist es besser, die Crawl-Delay-Anweisung nicht zu verwenden. Es ist so geschrieben:
Benutzeragent: Yandex
Crawl-Verzögerung: 4
Clean-param – wird nur von Yandex unterstützt und wird verwendet, um doppelte Seiten mit Variablen zu entfernen und sie zu einer zusammenzuführen. Daher lädt der Yandex-Roboter ähnliche Seiten nicht oft herunter, beispielsweise solche, die mit Empfehlungslinks verknüpft sind. Ich habe diese Anweisung noch nicht verwendet, aber in der Hilfe zu robots.txt für Yandex, folgen Sie dem Link am Anfang des Artikels, Sie können diese Anweisung im Detail lesen.
Die Sonderzeichen * und $ werden in robots.txt verwendet, um die Pfade der Disallow- und Allow-Anweisungen anzugeben:
- Das Sonderzeichen „*“ bezeichnet eine beliebige Zeichenfolge. Disallow: /*?* bedeutet beispielsweise ein Verbot aller Seiten, auf denen „?“ in der Adresse vorkommt, unabhängig davon, welche Zeichen vor und nach diesem Zeichen stehen. Standardmäßig wird das Sonderzeichen „*“ am Ende jeder Regel hinzugefügt, auch wenn es nicht ausdrücklich angegeben wird.
- Das „$“-Symbol hebt das „*“ am Ende der Regel auf und bedeutet strikte Übereinstimmung. Die Disallow: /*?$-Direktive verhindert beispielsweise die Indizierung von Seiten, die mit dem Zeichen „?“ enden.
Beispiel robots.txt für WordPress
Hier ist ein Beispiel meiner robots.txt-Datei für einen Blog auf der WordPress-Engine:
| Benutzeragent: * Nicht zulassen: /cgi-bin Nicht zulassen: /wp-admin Nicht zulassen: /wp-includes Nicht zulassen: /wp-content/plugins Nicht zulassen: /wp-content/cache Nicht zulassen: /wp-content/themes Nicht zulassen: / trackback Disallow: */trackback Disallow: */*/trackback Disallow: /feed/ Disallow: */*/feed/*/ Disallow: */feed Disallow: /*?* Disallow: /?s= User-agent: Yandex Nicht zulassen: /cgi-bin Nicht zulassen: /wp-admin Nicht zulassen: /wp-includes Nicht zulassen: /wp-content/plugins Nicht zulassen: /wp-content/cache Nicht zulassen: /wp-content/themes Nicht zulassen: /trackback Nicht zulassen: */ trackback Disallow: */*/trackback Disallow: /feed/ Disallow: */*/feed/*/ Disallow: */feed Disallow: /*?* Disallow: /?.ru/sitemap.xml..xml |
Benutzeragent: * Nicht zulassen: /cgi-bin Nicht zulassen: /wp-admin Nicht zulassen: /wp-includes Nicht zulassen: /wp-content/plugins Nicht zulassen: /wp-content/cache Nicht zulassen: /wp-content/themes Nicht zulassen: / trackback Disallow: */trackback Disallow: */*/trackback Disallow: /feed/ Disallow: */*/feed/*/ Disallow: */feed Disallow: /*?* Disallow: /?s= User-agent: Yandex Nicht zulassen: /cgi-bin Nicht zulassen: /wp-admin Nicht zulassen: /wp-includes Nicht zulassen: /wp-content/plugins Nicht zulassen: /wp-content/cache Nicht zulassen: /wp-content/themes Nicht zulassen: /trackback Nicht zulassen: */ trackback Disallow: */*/trackback Disallow: /feed/ Disallow: */*/feed/*/ Disallow: */feed Disallow: /*?* Disallow: /?.ru/sitemap.xml..xml
Um sich nicht die Mühe zu machen, die richtige robots.txt-Datei für WordPress zu erstellen, können Sie diese Datei verwenden. Es gibt keine Probleme mit der Indizierung. Ich habe ein Kopierschutzskript, sodass es bequemer ist, die vorgefertigte robots.txt herunterzuladen und auf Ihr Hosting hochzuladen. Vergessen Sie nur nicht, den Namen meiner Website in den Host- und Sitemap-Anweisungen durch Ihren zu ersetzen.
Nützliche Ergänzungen zum ordnungsgemäßen Einrichten der robots.txt-Datei für WordPress
Wenn Baumkommentare in Ihrem WordPress-Blog installiert sind, erstellen sie doppelte Seiten der Form ?replytocom= . In robots.txt werden solche Seiten mit der Direktive Disallow: /*?* geschlossen. Aber das ist keine Lösung und es ist besser, die Verbote aufzuheben und „replytocom“ auf andere Weise zu bekämpfen. Was, .
Somit sieht die aktuelle robots.txt mit Stand Juli 2014 so aus:
| Benutzeragent: * Nicht zulassen: /wp-includes Nicht zulassen: /wp-feed Nicht zulassen: /wp-content/plugins Nicht zulassen: /wp-content/cache Nicht zulassen: /wp-content/themes Benutzeragent: Yandex Nicht zulassen: /wp -includes Nicht zulassen: /wp-feed Nicht zulassen: /wp-content/plugins Nicht zulassen: /wp-content/cache Nicht zulassen: /wp-content/themes Host: site.ru Benutzeragent: Googlebot-Image Erlauben: /wp-content /uploads/ Benutzeragent: YandexImages Zulassen: /wp-content/uploads/ Sitemap: http://site.ru/sitemap.xml |
Benutzeragent: * Nicht zulassen: /wp-includes Nicht zulassen: /wp-feed Nicht zulassen: /wp-content/plugins Nicht zulassen: /wp-content/cache Nicht zulassen: /wp-content/themes Benutzeragent: Yandex Nicht zulassen: /wp -includes Nicht zulassen: /wp-feed Nicht zulassen: /wp-content/plugins Nicht zulassen: /wp-content/cache Nicht zulassen: /wp-content/themes Host: site.ru Benutzeragent: Googlebot-Image Erlauben: /wp-content /uploads/ Benutzeragent: YandexImages Zulassen: /wp-content/uploads/ Sitemap: http://site.ru/sitemap.xml
Darüber hinaus werden die Regeln für Bildindexierungsroboter festgelegt.
User-Agent: Mediapartners-Google
Nicht zulassen:
Wenn Sie Kategorie- oder Tag-Seiten bewerben möchten, sollten Sie diese für Robots öffnen. Auf einer Blog-Website sind beispielsweise Kategorien nicht von der Indexierung ausgeschlossen, da sie nur kleine Ankündigungen von Artikeln veröffentlichen, was im Hinblick auf die Duplizierung von Inhalten recht unbedeutend ist. Und wenn Sie die Anzeige von Zitaten im Blog-Feed nutzen, die mit einzigartigen Ankündigungen gefüllt sind, dann kommt es überhaupt nicht zu Duplikaten.
Wenn Sie das oben genannte Plugin nicht verwenden, können Sie in Ihrer robots.txt-Datei angeben, dass die Indizierung von Tags, Kategorien und Archiven verhindert werden soll. Fügen Sie beispielsweise die folgenden Zeilen hinzu:
Nicht zulassen: /Autor/
Nicht zulassen: /tag
Nicht zulassen: /category/*/*
Nicht zulassen: /20*
Vergessen Sie nicht, die robots.txt-Datei im Yandex.Webmaster-Panel zu überprüfen und sie dann erneut auf Ihr Hosting hochzuladen.
Wenn Sie Ergänzungen zur Konfiguration von robots.txt haben, schreiben Sie darüber in den Kommentaren. Sehen Sie sich jetzt ein Video darüber an, was es ist und wie Sie die richtige robots.txt-Datei für eine Site erstellen, wie Sie die Indizierung in der robots.txt-Datei verbieten und Fehler beheben.
Die robots.txt-Datei befindet sich im Stammverzeichnis Ihrer Site. Auf der Website www.example.com sieht die Adresse der robots.txt-Datei beispielsweise wie folgt aus: www.example.com/robots.txt. Die robots.txt-Datei ist eine Nur-Text-Datei, die dem Robot-Ausschlussstandard folgt und eine oder mehrere Regeln enthält, von denen jede einem bestimmten Crawler den Zugriff auf einen bestimmten Pfad auf der Website verweigert oder zulässt.
Hier ist ein Beispiel einer einfachen robots.txt-Datei mit zwei Regeln. Nachfolgend finden Sie Erläuterungen.
# Gruppe 1 User-Agent: Googlebot Disallow: /nogooglebot/ # Group 2 User-Agent: * Allow: / Sitemap: http://www.example.com/sitemap.xml
Erläuterungen
- Ein Benutzeragent namens Googlebot sollte das Verzeichnis http://example.com/nogooglebot/ und seine Unterverzeichnisse nicht crawlen.
- Alle anderen Benutzeragenten haben Zugriff auf die gesamte Site (kann weggelassen werden, das Ergebnis ist das gleiche, da standardmäßig voller Zugriff gewährt wird).
- Sitemap-Datei Diese Site befindet sich unter http://www.example.com/sitemap.xml.
Nachfolgend finden Sie einige Tipps zum Arbeiten mit robots.txt-Dateien. Wir empfehlen Ihnen, die vollständige Syntax dieser Dateien zu studieren, da die zu ihrer Erstellung verwendeten Syntaxregeln nicht offensichtlich sind und Sie sie verstehen müssen.
Format und Layout
Sie können eine robots.txt-Datei in fast jedem Texteditor erstellen, der die UTF-8-Kodierung unterstützt. Vermeiden Sie die Verwendung von Textverarbeitungsprogrammen, da diese Dateien häufig in einem proprietären Format speichern und illegale Zeichen wie geschweifte Anführungszeichen hinzufügen, die von Suchrobotern nicht erkannt werden.
Verwenden Sie beim Erstellen und Testen von robots.txt-Dateien ein Testtool. Es ermöglicht Ihnen, die Syntax einer Datei zu analysieren und herauszufinden, wie sie auf Ihrer Website funktionieren wird.
Regeln bezüglich Dateiformat und Speicherort
- Die Datei sollte robots.txt heißen.
- Es sollte nur eine solche Datei auf der Site geben.
- Die robots.txt-Datei muss eingefügt werden Wurzelverzeichnis Website. Um beispielsweise das Crawlen aller Seiten der Website http://www.example.com/ zu steuern, sollte sich die robots.txt-Datei unter http://www.example.com/robots.txt befinden. Es sollte sich nicht in einem Unterverzeichnis befinden(zum Beispiel an der Adresse http://example.com/pages/robots.txt). Wenn Sie Schwierigkeiten beim Zugriff auf das Stammverzeichnis haben, wenden Sie sich an Ihren Hosting-Anbieter. Wenn Sie keinen Zugriff auf das Stammverzeichnis der Site haben, verwenden Sie eine alternative Blockierungsmethode wie Meta-Tags.
- Die robots.txt-Datei kann mit zu Adressen hinzugefügt werden Subdomains(zum Beispiel http:// Webseite.example.com/robots.txt) oder nicht standardmäßige Ports (zum Beispiel http://example.com: 8181 /robots.txt).
- Jeder Text nach dem #-Symbol gilt als Kommentar.
Syntax
- Die robots.txt-Datei muss eine UTF-8-codierte Textdatei sein (die ASCII-Zeichencodes enthält). Andere Zeichensätze können nicht verwendet werden.
- Die robots.txt-Datei besteht aus Gruppen.
- Jede Gruppe kann mehrere enthalten Regeln, eine pro Zeile. Diese Regeln werden auch genannt Richtlinien.
- Die Gruppe umfasst die folgenden Informationen:
- Zu welchem User-Agent Es gelten die Gruppenrichtlinien.
- Zugang haben.
- Auf welche Verzeichnisse oder Dateien greift dieser Agent zu? Kein Zugang.
- Gruppenanweisungen werden von oben nach unten gelesen. Der Roboter befolgt nur die Regeln einer Gruppe mit dem Benutzeragenten, der ihm am ehesten entspricht.
- Standardmäßig wird davon ausgegangen dass der Benutzeragent ihn verarbeiten kann, wenn der Zugriff auf eine Seite oder ein Verzeichnis nicht durch eine Disallow:-Regel blockiert ist.
- Regeln Groß- und Kleinschreibung beachten. Daher gilt die Regel „Disallow: /file.asp“ für die URL http://www.example.com/file.asp, nicht jedoch für http://www.example.com/File.asp.
In robots.txt-Dateien verwendete Anweisungen
- User-Agent: Obligatorische Richtlinie, davon können mehrere in einer Gruppe vorhanden sein. Bestimmt die Suchmaschine Roboter Es müssen Regeln gelten. Jede Gruppe beginnt mit dieser Zeile. Die meisten Benutzeragenten im Zusammenhang mit Googlebots finden Sie in einer speziellen Liste und in der Internet Robots Database. Das Platzhalterzeichen * wird unterstützt, um ein Präfix, Suffix eines Pfads oder den gesamten Pfad anzugeben. Verwenden Sie das *-Zeichen wie im Beispiel unten gezeigt, um den Zugriff für alle Crawler zu blockieren ( außer AdsBot-Robotern, die separat angegeben werden muss). Wir empfehlen Ihnen, sich mit der Liste der Google-Robots vertraut zu machen. Beispiele:# Beispiel 1. Blockieren des Zugriffs nur auf Googlebot User-Agent: Googlebot Disallow: / # Beispiel 2. Blockieren des Zugriffs auf Googlebot und AdsBot-Robots User-Agent: Googlebot User-Agent: AdsBot-Google Disallow: / # Beispiel 3. Blockieren des Zugriffs auf alle Roboter, mit Ausnahme von AdsBot User-agent: * Disallow: /
- Nicht zulassen: . Verweist auf ein Verzeichnis oder eine Seite relativ zur Stammdomäne, die vom oben definierten Benutzeragenten nicht gecrawlt werden kann. Wenn es sich um eine Seite handelt, muss der vollständige Pfad zu dieser angegeben werden, wie in der Adressleiste des Browsers. Wenn es sich um ein Verzeichnis handelt, muss der Pfad mit einem Schrägstrich (/) enden. Das Platzhalterzeichen * wird unterstützt, um ein Präfix, Suffix eines Pfads oder den gesamten Pfad anzugeben.
- Erlauben: In jeder Gruppe muss mindestens eine Disallow:- oder Allow:-Anweisung vorhanden sein. Verweist auf ein Verzeichnis oder eine Seite relativ zur Stammdomäne, die vom oben definierten Benutzeragenten gecrawlt werden kann. Wird verwendet, um die Disallow-Anweisung zu überschreiben und das Scannen eines Unterverzeichnisses oder einer Seite in einem Verzeichnis zu ermöglichen, das zum Scannen geschlossen ist. Wenn es sich um eine Seite handelt, muss der vollständige Pfad zu dieser angegeben werden, wie in der Adressleiste des Browsers. Wenn es sich um ein Verzeichnis handelt, muss der Pfad mit einem Schrägstrich (/) enden. Das Platzhalterzeichen * wird unterstützt, um ein Präfix, Suffix eines Pfads oder den gesamten Pfad anzugeben.
- Seitenverzeichnis: Eine optionale Direktive; die Datei kann mehrere oder keine davon enthalten. Gibt den Speicherort der auf dieser Website verwendeten Sitemap an. Die URL muss vollständig sein. Google verarbeitet oder validiert keine URL-Variationen mit den Präfixen http und https oder mit oder ohne das www-Element. Sitemaps teilen Google mit, welchen Inhalt sie haben müssen scannen und wie man ihn von Inhalten unterscheidet Kann oder es ist verboten Scan. Beispiel: Sitemap: https://example.com/sitemap.xml Sitemap: http://www.example.com/sitemap.xml
Andere Regeln werden ignoriert.
Noch ein Beispiel
Die robots.txt-Datei besteht aus Gruppen. Jeder von ihnen beginnt mit einer User-Agent-Zeile, die den Roboter definiert, der die Regeln befolgen muss. Nachfolgend finden Sie ein Beispiel für eine Datei mit zwei Gruppen und erläuternden Kommentaren für beide.
# Blockieren Sie den Zugriff des Googlebots auf example.com/directory1/... und example.com/directory2/... #, erlauben Sie jedoch den Zugriff auf Verzeichnis2/subdirectory1/... # Der Zugriff auf alle anderen Verzeichnisse ist standardmäßig zulässig. User-Agent: googlebot Disallow: /directory1/ Disallow: /directory2/ Allow: /directory2/subdirectory1/ # Blockieren Sie den Zugriff auf die gesamte Website für eine andere Suchmaschine. Benutzeragent: anothercrawler Disallow: /
Vollständige Syntax der robots.txt-Datei
Die vollständige Syntax wird in diesem Artikel beschrieben. Wir empfehlen Ihnen, sich damit vertraut zu machen, da die Syntax der robots.txt-Datei einige wichtige Nuancen aufweist.
Nützliche Regeln
Hier sind einige allgemeine Regeln für die robots.txt-Datei:
| Regel | Beispiel |
|---|---|
| Verbot des Crawlens der gesamten Website. Bitte beachten Sie, dass in einigen Fällen Website-URLs im Index vorhanden sein können, auch wenn sie nicht gecrawlt wurden. Bitte beachten Sie, dass diese Regel nicht für AdsBot-Robots gilt, die separat angegeben werden müssen. | Benutzeragent: * Nicht zulassen: / |
| Um das Scannen eines Verzeichnisses und seines gesamten Inhalts zu verhindern, fügen Sie nach dem Verzeichnisnamen einen Schrägstrich ein. Verwenden Sie die robots.txt-Datei nicht zum Schutz vertraulicher Informationen! Für diese Zwecke sollte die Authentifizierung verwendet werden. URLs, die von der robots.txt-Datei nicht gecrawlt werden dürfen, können indiziert werden, und der Inhalt der robots.txt-Datei kann von jedem Benutzer eingesehen werden und so den Speicherort von Dateien mit vertraulichen Informationen offenlegen. | Benutzeragent: * Nicht zulassen: /calendar/ Nicht zulassen: /junk/ |
| Um das Crawlen nur durch einen Crawler zu ermöglichen | Benutzeragent: Googlebot-news Zulassen: / Benutzeragent: * Nicht zulassen: / |
| Um das Crawlen für alle Crawler außer einem zu ermöglichen | User-Agent: Unnecessarybot Disallow: / User-Agent: * Allow: / |
|
Um zu verhindern, dass eine bestimmte Seite gecrawlt wird Geben Sie diese Seite nach dem Schrägstrich an. |
Benutzeragent: * Nicht zulassen: /private_file.html |
|
Um ein bestimmtes Bild vor dem Google Bilder-Roboter auszublenden |
User-Agent: Googlebot-Image Disallow: /images/dogs.jpg |
|
Um alle Bilder Ihrer Website vor dem Google Bilder-Roboter auszublenden |
User-Agent: Googlebot-Image Disallow: / |
|
Um zu verhindern, dass alle Dateien eines bestimmten Typs gescannt werden(in diesem Fall GIF) |
User-Agent: Googlebot Disallow: /*.gif$ |
|
Um bestimmte Seiten Ihrer Website zu blockieren, auf denen jedoch weiterhin AdSense-Anzeigen geschaltet werden sollen, verwenden Sie die Disallow-Regel für alle Robots außer Mediapartners-Google. Dadurch kann dieser Roboter auf Seiten zugreifen, die aus den Suchergebnissen entfernt wurden, um Anzeigen auszuwählen, die einem bestimmten Benutzer angezeigt werden sollen. |
User-Agent: * Disallow: / User-Agent: Mediapartners-Google Allow: / |
| Um eine URL anzugeben, die bei einem bestimmten Fragment endet, verwenden Sie das $-Symbol. Verwenden Sie beispielsweise für URLs, die auf .xls enden, den folgenden Code: | User-Agent: Googlebot Disallow: /*.xls$ |
Waren diese Informationen nützlich?
Wie kann dieser Artikel verbessert werden?
Einer der Schritte zur Optimierung einer Website für Suchmaschinen ist das Kompilieren einer robots.txt-Datei. Mithilfe dieser Datei können Sie verhindern, dass einige oder alle Suchroboter Ihre Website oder bestimmte Teile davon, die nicht für die Indexierung vorgesehen sind, indizieren. Insbesondere können Sie verhindern, dass doppelte Inhalte indiziert werden, beispielsweise druckbare Versionen von Seiten.
Bevor Sie mit der Indizierung beginnen, verweisen Suchroboter immer auf die Datei robots.txt im Stammverzeichnis Ihrer Website, zum Beispiel http://site.ru/robots.txt, um zu erfahren, welche Abschnitte der Website für den Roboter verboten sind aus der Indizierung. Aber auch wenn Sie nichts verbieten möchten, empfiehlt es sich dennoch, diese Datei zu erstellen.
Wie Sie an der Erweiterung robots.txt erkennen können, handelt es sich hierbei um eine Textdatei. Um diese Datei zu erstellen oder zu bearbeiten, ist es besser, die einfachsten Texteditoren wie Notepad zu verwenden. robots.txt muss im Stammverzeichnis der Site abgelegt werden und hat ein eigenes Format, das wir weiter unten besprechen werden.
Robots.txt-Dateiformat
Die robots.txt-Datei muss mindestens zwei erforderliche Einträge enthalten. Die erste ist die User-Agent-Anweisung, die angibt, welcher Suchroboter den nachfolgenden Anweisungen folgen soll. Der Wert kann der Name des Roboters (Googlebot, Yandex, StackRambler) oder das *-Symbol sein, wenn Sie auf alle Roboter gleichzeitig zugreifen. Zum Beispiel:
User-Agent: GooglebotDen Namen des Roboters finden Sie auf der Website der entsprechenden Suchmaschine. Als nächstes sollte es eine oder mehrere Disallow-Anweisungen geben. Diese Anweisungen teilen dem Roboter mit, welche Dateien und Ordner nicht indiziert werden dürfen. Die folgenden Zeilen verhindern beispielsweise, dass Robots die Datei „feedback.php“ und das Verzeichnis „cgi-bin“ indizieren:
Nicht zulassen: /feedback.php Nicht zulassen: /cgi-bin/Sie können auch nur die Anfangszeichen von Dateien oder Ordnern verwenden. Die Zeile Disallow: /forum verhindert die Indizierung aller Dateien und Ordner im Stammverzeichnis der Site, deren Name mit forum beginnt, zum Beispiel der Datei http://site.ru/forum.php und des Ordners http://site. ru/forum/ mit all seinem Inhalt. Wenn Disallow leer ist, bedeutet dies, dass der Robot alle Seiten indizieren kann. Wenn der Disallow-Wert das /-Symbol ist, bedeutet dies, dass die gesamte Website nicht indiziert werden darf.
Für jedes User-Agent-Feld muss mindestens ein Disallow-Feld vorhanden sein. Das heißt, wenn Sie nichts für die Indizierung verbieten möchten, sollte die robots.txt-Datei die folgenden Einträge enthalten:
Benutzeragent: * Nicht zulassen:Zusätzliche Richtlinien
Zusätzlich zu regulären Ausdrücken erlauben Yandex und Google die Verwendung der Allow-Direktive, die das Gegenteil von Disallow ist, das heißt, sie gibt an, welche Seiten indiziert werden können. Im folgenden Beispiel ist es Yandex untersagt, alles außer Seitenadressen zu indizieren, die mit /articles beginnen:
Benutzeragent: Yandex Zulassen: /articles Nicht zulassen: /In diesem Beispiel muss die Allow-Anweisung vor Disallow geschrieben werden, da Yandex dies sonst als vollständiges Verbot der Indizierung der Website versteht. Eine leere Allow-Anweisung deaktiviert auch die Site-Indizierung vollständig:
Benutzeragent: Yandex Zulassen:Äquivalent
Benutzeragent: Yandex Disallow: /Nicht standardmäßige Anweisungen müssen nur für diejenigen Suchmaschinen angegeben werden, die sie unterstützen. Andernfalls könnte ein Roboter, der diesen Eintrag nicht versteht, ihn oder die gesamte robots.txt-Datei falsch verarbeiten. Weitere Informationen zu zusätzlichen Anweisungen und allgemein zum Verständnis von Befehlen in der robots.txt-Datei durch einen einzelnen Roboter finden Sie auf der Website der entsprechenden Suchmaschine.
Reguläre Ausdrücke in robots.txt
Die meisten Suchmaschinen berücksichtigen nur explizit angegebene Datei- und Ordnernamen, es gibt aber auch fortgeschrittenere Suchmaschinen. Google Robot und Yandex Robot unterstützen die Verwendung einfacher regulärer Ausdrücke in robots.txt, was den Arbeitsaufwand für Webmaster deutlich reduziert. Die folgenden Befehle verhindern beispielsweise, dass Googlebot alle Dateien mit der Erweiterung .pdf indiziert:
User-Agent: Googlebot Nicht zulassen: *.pdf$Im obigen Beispiel ist * eine beliebige Zeichenfolge und $ gibt das Ende des Links an.
Benutzeragent: Yandex Zulassen: /articles/*.html$ Nicht zulassen: /Die oben genannten Anweisungen ermöglichen Yandex, nur Dateien mit der Erweiterung „.html“ zu indizieren, die sich im Ordner /articles/ befinden. Alles andere ist für die Indizierung verboten.
Seitenverzeichnis
Sie können den Speicherort der XML-Sitemap in der robots.txt-Datei angeben:
User-Agent: googlebot Nicht zulassen: Sitemap: http://site.ru/sitemap.xmlWenn Ihre Website sehr viele Seiten hat und Sie die Sitemap in Teile aufteilen mussten, müssen Sie alle Teile der Karte in der robots.txt-Datei angeben:
Benutzeragent: Yandex Disallow: Sitemap: http://mysite.ru/my_sitemaps1.xml Sitemap: http://mysite.ru/my_sitemaps2.xmlSite-Spiegel
Wie Sie wissen, kann dieselbe Site normalerweise unter zwei Adressen aufgerufen werden: sowohl mit www als auch ohne. Für einen Suchroboter sind site.ru und www.site.ru unterschiedliche Websites, aber mit demselben Inhalt. Sie werden Spiegel genannt.
Aufgrund der Tatsache, dass es Links zu den Seiten der Website sowohl mit als auch ohne www gibt, kann das Gewicht der Seiten zwischen www.site.ru und site.ru aufgeteilt werden. Um dies zu verhindern, muss die Suchmaschine den Hauptspiegel der Website angeben. Durch das „Kleben“ gehört das gesamte Gewicht einem Hauptspiegel und die Website kann in den Suchergebnissen eine höhere Position einnehmen.
Sie können den Hauptspiegel für Yandex direkt in der robots.txt-Datei mit der Host-Direktive angeben:
Benutzeragent: Yandex Nicht zulassen: /feedback.php Nicht zulassen: /cgi-bin/ Host: www.site.ruNach dem Kleben übernimmt der Spiegel www.site.ru das gesamte Gewicht und nimmt eine höhere Position in den Suchergebnissen ein. Und die Suchmaschine indiziert site.ru überhaupt nicht.
Bei anderen Suchmaschinen ist die Wahl des Hauptspiegels eine serverseitige permanente Weiterleitung (Code 301) von zusätzlichen Spiegeln zum Hauptspiegel. Dies erfolgt über die .htaccess-Datei und das Modul mod_rewrite. Legen Sie dazu die .htaccess-Datei im Stammverzeichnis der Site ab und schreiben Sie dort Folgendes:
RewriteEngine On-Optionen +FollowSymlinks RewriteBase / RewriteCond %(HTTP_HOST) ^site.ru$ RewriteRule ^(.*)$ http://www.site.ru/$1Infolgedessen werden alle Anfragen von site.ru an www.site.ru weitergeleitet, d. h. site.ru/page1.php wird an www.site.ru/page1.php umgeleitet.
Die Umleitungsmethode funktioniert für alle Suchmaschinen und Browser, es wird jedoch dennoch empfohlen, die Host-Anweisung zur robots.txt-Datei für Yandex hinzuzufügen.
Kommentare in robots.txt
Sie können der robots.txt-Datei auch Kommentare hinzufügen – sie beginnen mit dem #-Symbol und enden mit einer neuen Zeile. Es empfiehlt sich, Kommentare in einer separaten Zeile zu verfassen oder besser darauf zu verzichten.
Ein Beispiel für die Verwendung von Kommentaren:
Benutzeragent: StackRambler Disallow: /garbage/ # in diesem Ordner Disallow: /doc.xhtml # und auch auf dieser Seite # und alle Kommentare in dieser Datei sind ebenfalls nutzlosBeispiele für robots.txt-Dateien
1. Erlauben Sie allen Robots, alle Site-Dokumente zu indizieren:
Benutzeragent: * Nicht zulassen:Benutzeragent: * Nicht zulassen: /
3. Wir untersagen dem Google-Suchroboter, die Datei „feedback.php“ und den Inhalt des cgi-bin-Verzeichnisses zu indizieren:
User-Agent: googlebot Disallow: /cgi-bin/ Disallow: /feedback.php4. Wir erlauben allen Robots, die gesamte Website zu indizieren, und wir verbieten dem Yandex-Suchmaschinen-Roboter, die Datei „feedback.php“ und den Inhalt des cgi-bin-Verzeichnisses zu indizieren:
Benutzeragent: Yandex Nicht zulassen: /cgi-bin/ Nicht zulassen: /feedback.php Host: www.site.ru Benutzeragent: * Nicht zulassen:5. Wir erlauben allen Robotern, die gesamte Website zu indizieren, und wir erlauben dem Yandex-Roboter, nur den für ihn vorgesehenen Teil der Website zu indizieren:
User-Agent: Yandex Zulassen: /yandex Disallow: / Host: www.site.ru User-Agent: * Disallow:Leerzeilen trennen Einschränkungen für verschiedene Roboter. Jeder Einschränkungsblock muss mit einer Zeile mit dem Feld „User-Agent“ beginnen, die den Robot angibt, für den diese Site-Indizierungsregeln gelten.
Häufige Fehler
Es ist wichtig zu berücksichtigen, dass eine leere Zeile in der robots.txt-Datei ein Trennzeichen zwischen zwei Einträgen für verschiedene Roboter ist. Sie können auch nicht mehrere Anweisungen in einer Zeile angeben. Wenn Webmaster verhindern, dass eine Datei indiziert wird, lassen sie häufig das / vor dem Dateinamen weg.
Es ist nicht erforderlich, in robots.txt ein Verbot der Indizierung der Site für verschiedene Programme anzugeben, die darauf ausgelegt sind, die Site vollständig herunterzuladen, beispielsweise TeleportPro. Weder Download-Programme noch Browser schauen sich diese Datei jemals an und führen die dort geschriebenen Anweisungen aus. Es ist ausschließlich für Suchmaschinen bestimmt. Sie sollten auch nicht das Admin-Panel Ihrer Site in robots.txt blockieren, denn wenn es nirgendwo einen Link dazu gibt, wird sie nicht indiziert. Sie geben lediglich den Standort des Admin-Bereichs an Personen weiter, die nichts davon wissen sollten. Bedenken Sie auch, dass eine zu große robots.txt-Datei möglicherweise von der Suchmaschine ignoriert wird. Wenn Sie zu viele Seiten haben, die nicht für die Indizierung vorgesehen sind, ist es besser, sie einfach von der Site zu entfernen oder in ein separates Verzeichnis zu verschieben und die Indizierung dieses Verzeichnisses zu verhindern.
Überprüfen Sie die robots.txt-Datei auf Fehler
Überprüfen Sie unbedingt, wie Suchmaschinen Ihre Robots-Datei verstehen. Um Google zu überprüfen, können Sie die Google Webmaster-Tools verwenden. Wenn Sie herausfinden möchten, wie Ihre robots.txt-Datei von Yandex verstanden wird, können Sie den Dienst Yandex.Webmaster nutzen. So können Sie etwaige Fehler zeitnah korrigieren. Auch auf den Seiten dieser Dienste finden Sie Empfehlungen zum Erstellen einer robots.txt-Datei und viele weitere nützliche Informationen.
Das Kopieren des Artikels ist untersagt.